

Les jointures font toute la puissance des bases de données relationnelles et sont la raison profonde de la popularité du SQL. Voyons cette fois-ci comment cela se traduit en R avec dplyr.
Rappels fonctionnels : Qu’est-ce qu’une jointure ?
Une jointure est la mise en relation de données de tables différentes au travers d’un ou plusieurs champs communs entre elles.
Les contraintes
Cela entraine plusieurs impératifs tant en SQL qu’en R :
- Les champs servant à la jointure doivent appartenir à chaque table
- Ils doivent être de même type (ou pour R de type suffisamment compatible)
- Il faut prévoir la gestion des valeurs
NULL(sql) ouNA(R)
Les types de relations
Une fois les contraintes intrinsèques (liées au contenu des champs de la table elle-même) ci-dessus posées, il existe des contraintes extrinsèques (liées aux champs des tables source et destination de la jointure) :
- Il faut maitriser la cardinalité de la jointure, c’est à dire si il s’agit d’une relation
- « un à un » : 1 enregistrement de la table source correspond à un et un seul enregistrement de la table destination
- « un à zéro ou un » (variation de la précédente)
- « un à plusieurs » (et « un à zéro ou plusieurs ») : 1 enregistrement de la table source correspond à plusieurs enregistrements de la table destination
- « plusieurs à un » (et « plusieurs à zéro ou un ») : plusieurs enregistrements de la table source correspond à un et un seul enregistrement de la table destination
- Et enfin « plusieurs à plusieurs » : plusieurs enregistrements de la table source correspond à plusieurs enregistrements de la table destination
La notion d’index et de clé primaire
Un index est un champ remarquable au sein d’une table car il permet une recherche rapide de son contenu soit dans le but de l’utiliser dans un filtre, soit pour permettre les fameuses jointures. Une table peut contenir un nombre variable d’index.
En SQL
Dans une base de données, cela passe par la création explicite des index dans la définition de la table (on dit le schéma). Il y a certaines limitations :
- Créer un index peut occuper beaucoup de place donc souvent tous les champs ne sont pas indexés
- Tous les types de champs ne peuvent pas être des index (par exemple les blobs ou les champs de longueur non définie)
- Le créateur doit idéalement définir par une contrainte si la valeur NULL est autorisée au sein de l’index
- Si une valeur peut être présente plusieurs fois (CREATE UNIQUE INDEX)
- Et il est possible de créer des index composites, portant sur plusieurs champs simultanément.
Typiquement en SQL, on écrit :
-- Pour un index ou les répétions de valeur sont possibles :
CREATE INDEX `nom de l'index` ON `nom de la table` (`champs à indexer`);
-- si on interdit les valeurs répétées :
CREATE UNIQUE INDEX `nom de l'index` ON `nom de la table` (`champs à indexer`);Il existe par ailleurs un type particulier d’index qui peut (et normalement DOIT si on fait les choses proprement) être défini : la clé primaire. En pratique, c’est un index de type UNIQUE, excluant la valeur nulle et qui identifie chaque enregistrement de la table de façon unique. Sa définition se fait lors de la création de la table en précisant PRIMARY KEY dans la définition du champ. Cela s’écrit :
CREATE TABLE nom_de_la_table (
cle_enregistrement INT PRIMARY KEY NOT NULL AUTO_INCREMENT,
[...]
);Et en R ?
R n’a pas tout cela pour une raison simple : Toutes les données d’un data.frame sont en fait plus ou moins indexées… Cela tient dans la nature même du stockage en mémoire des données.1 Et tous les data.frames disposent d’un index implicite (le row_number qui est un entier positif croissant en continu sur toute la table). Vous n’aurez pas à gérer quoi que ce soit, R fera au mieux.
Les différents types de jointure
dplyr définit 3 types de jointures, en SQL on a le 1 et 3ème type et parfois le second :
- les mutating joins (les jointures de mutation de données) qui donnent en sortie une nouvelle table de données prenant celles-ci dans les tables sources. C’est l’équivalent des jointures SQL standard (
INNER JOIN,LEFT/RIGHT (OUTER) JOIN,FULL JOIN) - les filtering joins (jes jointures de filtre) qui donnent en sortie une sous-sélection de lignes de la table de gauche sans rajouter des nouvelles colonnes. Certains SQBDRs ont ces fonctions ou à défaut il faut utiliser des sous-requêtes avec
EXISTS(). - et enfin le
CROSS JOIN(produit cartésien)
Sans plus tarder entrons dans le vif du sujet !
Les CROSS JOIN
Commençons par celui que normalement vous n’utiliserez jamais directement. Le CROSS JOIN s’écrit en SQL :
-- Cross join explicite
SELECT A.*, B.*
FROM A CROSS JOIN B;
-- Cross join implicite (version historique)
SELECT A.*, B.*
FROM A, B;
En R/dplyr, on peut utiliser cross_join() :
A %>% cross_join(B)Le CROSS JOIN est plus un concept qui sous-tend les autres jointures (raison pour laquelle j’en parle en premier mais on ne le reverra pas). Il crée une table résultat avec une relation « plusieurs à plusieurs » entre TOUS les enregistrements. L’une des conséquences absolument pas pratique et que la table résultat a une taille monstrueuse de nrow(A) * nrow(B). 2 tables de chacune 1000 lignes, créent un cross join de 1 millions d’enregistrements !
L’exemple le plus typique de l’utilisation d’un cross join est avec une clause WHERE entre les tables :
SELECT A.*, B.*
FROM A, B
WHERE A.id = B.id_A;
-- Dans les faits, c'est un INNER JOIN
SELECT A.*, B.*
FROM A INNER JOIN B ON A.id = B.id_A;Créer toutes les associations puis les filtrer est une énorme perte de temps et de ressources : utilisez plutôt les autres types de jointures !
En gros, sauf besoin très spécifique d’un produit cartésien entre A et B de petite taille, jamais vous n’utiliserez le CROSS JOIN/cross_join() surtout en R où vous allez faire crasher l’allocateur de mémoire très rapidement si les tables sources sont trop grosses (dplyr, rappelons-le travaille sur des objets entièrement stockés en mémoire).
Le prototype commun en dplyr
Toutes les fonctions de jointures de dplyr s’écrivent de la même façon. Dans un pipeline, on écrira
`A` %>% *_join(`B`, by = c(liste de noms de champs) )
# ou
`A` %>% *_join(`B`, join_by(clauses de jointure) )
où « *_join() » est l’une des fonctions de jointure (inner, left, right, full, semi, anti)
« liste de noms de champs » est une liste crée en passant à la fonction c() (la fonction de concaténation) des couples de noms de colonnes : "nom_dans_la_table_1" = "nom_dans_la_table_2")
Nous verrons des exemples plus parlants ci dessous.
Si vous ne passez pas de paramètre by= ou de join_by(), dplyr tentera de faire au mieux en faisant une jointure entre tous les champs ayant le même nom dans la table de gauche et celle de droite. Assez souvent ce sera un échec donc je serais vous, je préciserais toujours les champs de jointure !
Les mutating joins
Ce sont les jointures les plus courantes, elles se composent d’une table gauche, d’une table droite et d’un ensemble de champs pivots.
On retrouve exactement le pendant des jointures SQL : inner_join(), left_join(), right_join(), full_join(). Pour rappel voici un schéma des données sélectionnées dans chacun des cas :
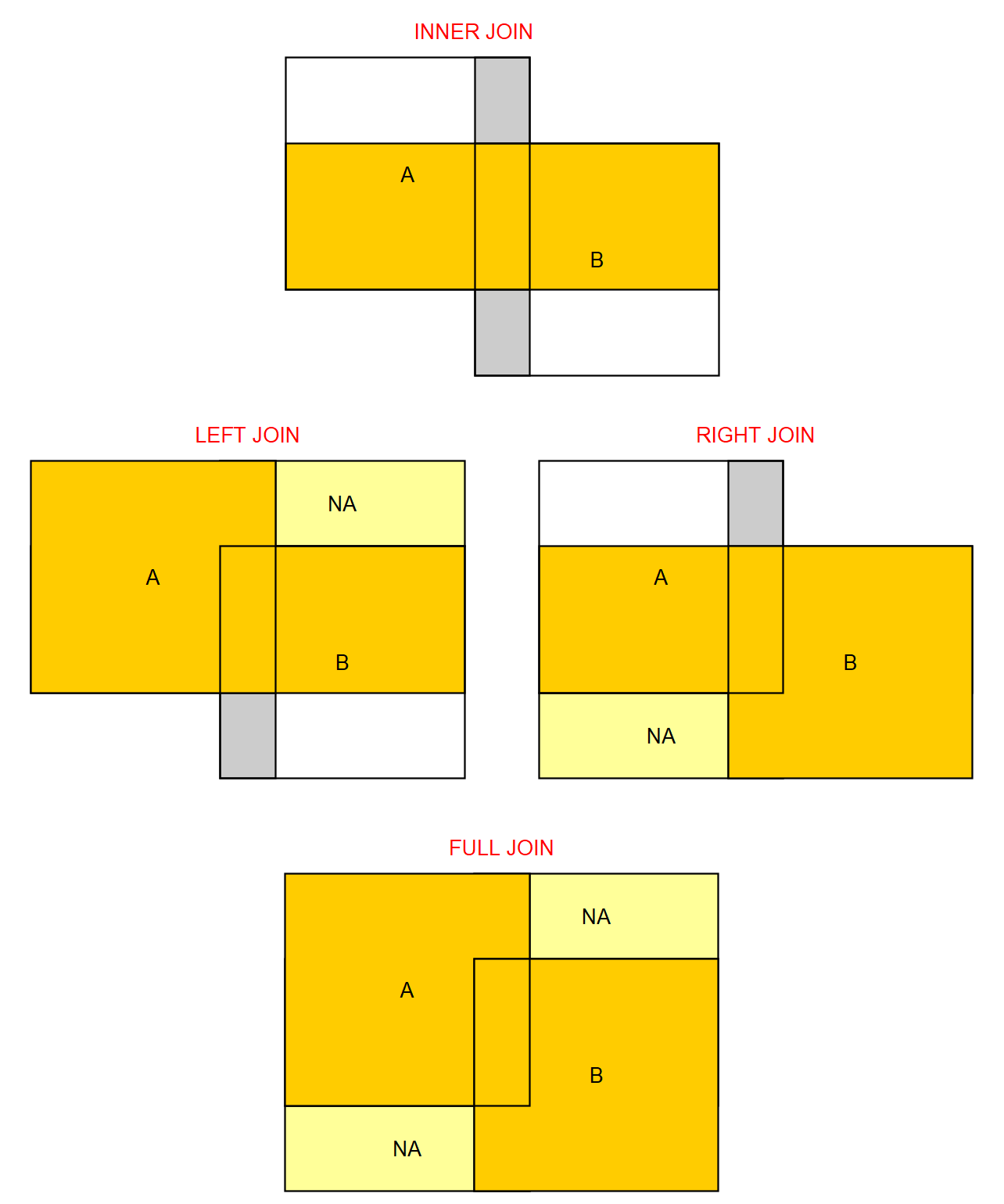
L’exemple le plus simple est :
SELECT rss.NDA,rss.NRSS, vidhosp.IPP
FROM rss INNER JOIN vidhosp ON rss.NDA = vidhosp.NDA;C’est à dire « prend les tables rss et vidhosp, isole les enregistrements de chaque table où le champ NDA est égal, colle les données côte à côte et limite l’affichage aux colonnes NDA, NRSS et IPP »
En R, cela s’écrit pareil dans le pipeline :
rss %>%
inner_join(vidhosp, by = "NDA") %>%
select(NDA, NRSS, IPP)
# ou bien avec join_by()
rss %>%
inner_join(vidhosp, join_by(NDA)) %>%
select(NDA, NRSS, IPP)
Les filtering joints
Les jointures de filtre n’existent pas en SQL standard mais certains SGBDs les rajoutent en non standard. Elles ne modifient pas la structure de la table résultat qui aura les mêmes colonnes que la table A :
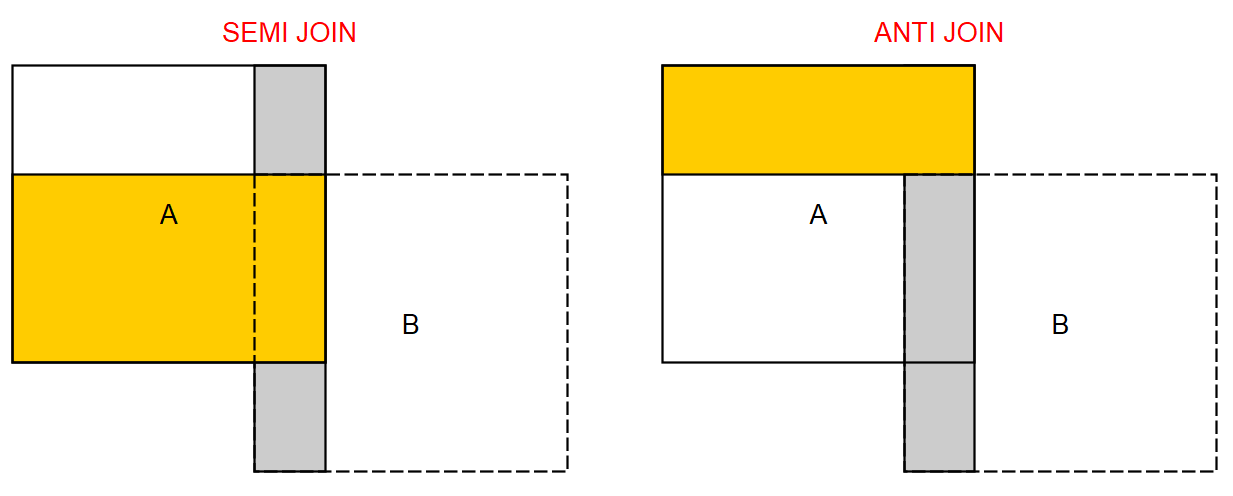
Ce sont des raccourcis bien pratiques car très régulièrement utilisés dans les traitements. Quand le SGBD n’a pas la fonction, SEMI JOIN correspond à :
-- SEMI JOIN
SELECT A.*
FROM A
WHERE EXISTS (
SELECT 1
FROM B
WHERE B.id_A = A.id
);Soit en R :
A %>% semi_join(B, by = c("id" = "id_A"))Et ANTI JOIN :
-- ANTI JOIN
SELECT A.*
FROM A
WHERE NOT EXISTS (
SELECT 1
FROM B
WHERE B.id_A = A.id
);
-- LEFT JOIN avec filtre sur NULL
SELECT A.*
FROM A
LEFT JOIN B ON A.id = B.id_A
WHERE B.id_A IS NULL;En R :
A %>% anti_join(B, by = c("id" = "id_A"))
# une version sans jointure pourrait s'écrire
A %>% filter(!(id %in% B$id_A))Tout de même beaucoup plus concis.
Le cas des jointures multiples
Il est très courant en SQL de faire de multiples jointures au sein d’une même stance, par exemple :
SELECT A.*, B.*, C.*
FROM A
LEFT JOIN B ON A.id = B.id_A
LEFT JOIN C ON B.id = C.id_B;En R, on peut le traduire de plusieurs façons mais il y a un piège :
#Ex. 1
A %>%
left_join(B %>%
left_join(C, by = c("id" = "id_B")),
by = c("id" = "id_A"))
# ou alors (Ex. 2)
A %>%
left_join(B, by = c("id" = "id_A"), suffix = c(".A",".B")) %>%
left_join(C, by = c("id.B" = "id_B")
Ici nous faisons d’abord les jointures de façon imbriquées : Nous allons récupérer le résultat du left_join() de B et C et faire le left_join() avec A. Et ensuite une version « à plat ».
MAIS dans les 2 cas, il y a un problème n’existant pas en SQL : les homonymes de noms de champs. En SQL, dans le verbe principal, nous devons nommer explicitement les tables sources, mais pas en R. Or le champ « id » existe ici au final dans A, B (et peut être même dans C) !
Il y a 2 façons de s’en sortir :
- Nativement (comme détaillé dans l’exemple 2), on peut utiliser le paramètre
suffix=qui va définir un suffixe qui sera ajouté à chaque nom de colonne selon sa table d’origine seulement s’il est en collision entre les 2 tables. - Avec une modification explicite du nom des champs pour forcer un comportement comme le SQL. C’est l’objet de la fonction que je vous ai écrite dans le 1er article de la série :
prefix()
L’avantage de la 2ème solution est que, même si elle est plus verbeuse, elle est aussi plus stricte et prévisible :
# Ex. 3
A %>% prefix("A") %>%
left_join(B %>% prefix("B"), by = c("A.id" = "B.id_A")) %>%
left_join(C %>% prefix("C"), by = c("B.id" = "C.id_B"))
# Toutes les colonnes de A s'appellent A.[nom original]
# Toutes les colonnes de B s'appellent B.[nom original] sauf id_A qui est absente
# Toutes les colonnes de C s'appellent C.[nom original] sauf id_B qui est absenteSachant que A, B, C contiennent des champs « id », sauriez-vous prévoir le nom des champs dans le résultat pour chaque exemple ? (cliquez pour voir la réponse)
| Exemple 1 | Toutes les colonnes de A s’appellent [non original] sauf celles qui existent dans B ou C qui s’appelleront [non original].x Toutes les colonnes de B s’appellent [non original] sauf celles qui existent dans C qui s’appelleront [non original].x et celles qui existent dans A s’appelleront [non original].y sauf id_A qui est absente Toutes les colonnes de C s’appellent [non original] sauf celles qui existent dans B qui s’appelleront [non original].x et celles qui existent dans A s’appelleront [non original].y sauf id_B qui est absente |
| Exemple 2 | Toutes les colonnes de A s’appellent [non original] sauf celles qui existent dans B qui s’appelleront [non original].A Toutes les colonnes de B s’appellent [non original] sauf celles qui existent dans C qui s’appelleront [non original].B et celles qui existent dans A s’appelleront [non original].B sauf id_A qui est absente Toutes les colonnes de C s’appellent [non original] sauf celles qui existent dans C qui s’appelleront [non original].C sauf id_B qui est absente |
| Exemple 3 | Toutes les colonnes de A s’appellent A.[nom original] Toutes les colonnes de B s’appellent B.[nom original] sauf id_A qui est absente Toutes les colonnes de C s’appellent C.[nom original] sauf id_B qui est absente |
Alors au final quelle version préférez-vous ? (La bonne réponse est « aucune, je m’adapte en fonction de mon jeu de données » 😉, c’est aussi ça faire du R savoir quand être strict ou pas)
Un dernier cas tordu : si en rajoutant l’affixe, cela crée un nom de colonne qui existe, alors la règle du suffix= s’appliquera, mais pour en arriver là c’est qu’on connait très mal son jeu de données ou qu’on l »a mal pensé !
Si vous ne maitrisez pas les champs que vous allez recevoir, ou si vous risquez d’avoir des problèmes de lisibilité, je vous conseille d’affixer vos tables. Je vous le conseille aussi très fortement si vous allez jointurer plusieurs fois la même table (par exemple, si vous faites une jonction du VIDHOSP sur le RSS pour la mère et l’enfant via le NDA, il vous faudra 2 fois jointurer la table RSS et vous aurez alors systématiquement des doublons autant affixer intelligemment avec « enfant » et « mere » par exemple)
Une autre possibilité est de prétraiter vos tables si c’est possible car rien n’empêche de faire un select() ou un rename() préalable, c’est l’équivalent d’une sous-requête en SQL
A %>%
left_join(B %>% rename(B.id = id), by= c("id" = "id_A")) %>%
left_join(C %>% rename(C.id = id), by = c("B.id" = "id_B")
La fonction join_by()
Je vous ai parlé plus haut de l’utilisation de join_by() en remplacement du paramètre by=. C’est une évolution récente de dplyr alors autant s’en servir ! Il est temps d’explorer ses avantages plus avant.
Tout d’abord, join_by() peut être le paramètre de by= ou être saisi sans.
# Ecrire
A %>% inner_join(B, by = "id")
# est équivalent à
A %>% inner_join(B, by = join_by(id))
# ou à
A %>% inner_join(B, join_by(id))Autre particularité, join_by() est une « vraie » fonction qui retourne un objet dplyr_join_by qui pourra être utilisé ou réutilisé à tout moment. Donc il est tout à fait possible de préparer une jointure en avance, il n’y a même pas besoin de connaitre les tables à cette étape.
Par exemple, on peut dire que la jointure entre un RSS et un VIDHOSP est une jointure composite sur 3 champs (dans le cas où on manipulerait des fichiers multi-établissements) : FINESS, NDA, NRSS et le retranscrire ainsi :
# jointure pour un by :
by_NRSS <- c("FINESS", "NDA","NRSS")
rss %>% inner_join(vidhosp, by = by_NRSS)
# by= attend une liste de noms de champs pivots donc un vecteur de chaines
# ou avec join_by :
by_NRSS <- join_by(FINESS, NDA, NRSS)
rss %>% inner_join(vidhosp, by_NRSS)
# by_NRUM est ici un objet de type dplyr_join_byCela peut avoir un intérêt pour simplifier la lecture de certains enchainements de commande.
Cependant l’intérêt principal de join_by() est surtout dans sa plus grande souplesse sur les règles de jointure.
La où by= n’accepte que les jointure par égalité stricte, join_by() permet d’utiliser beaucoup plus d’options qui ne sont pas transposables depuis SQL :
- Les égalités de clés (comme
by=) bien sûr avecjoin_by(NDA)oujoin_by(A.NDA==B.NDA)(Notez le égal-égal comme lorsqu’on écrit un filtre) - Les comparaisons numériques avec
>, >=, <, <= - Les comparaisons d’intervalle avec
between(), within(),overlaps() - La valeur la plus proche avec
closest()
Et bien sûr toutes ces jointures sont cumulables, il suffit de les rajouter les unes à la suite des autrs dans le join_by() séparées par des virgules. Pour plus de précision dans les opérations, il est possible de préciser si on parle de la table de gauche (appelée arbitrairement x), ou de la table de droite (appelée y).
Ce que l’on ne peut pas faire : des anti_jointures (!= n’existe pas), des jointures sur des champs calculés à la volée (il faut créer la nouvelle valeur calculée via un mutate() avant d’appliquer la jointure sur ce nouveau champ)
Ces possibilités n’existant pas en SQL, il vous faudra faire une petite gymnastique intellectuelle pour y penser lorsque vous en aurez besoin. Mais détachez-vous progressivement de la logique SQL et vous y arriverez. Voici quelques exemples de mise en oeuvre :
# Le RUM qui contient l'administration de chaque molécule d'un fichcomp :
fc06 %>% inner_join(rss, join_by(finess, nda, between(date, entree, sortie, bounds="[)"))
# un bémol sur les administrations le jour d'un mouvement d'UF car
# les données n'ont pas la granularité suffisante (jour seulement)
# Tous les séjours postérieurs à un séjour principal d'un patient
vidhosp %>%
filter(nda = "1234567A") %>%
inner_join(vidhosp, join_by(ipp, x$sortie < y$entree)
# Chaque séjour et son séjour suivant
vidhosp %>% inner_join(vidhosp, join_by(ipp, closest(x$sortie < y$entree)))Il y a un petit piège l’avez-vous trouvé ? (cliquez pour la réponse)
Il faudra traiter c’est le cas de la réhospitalisation le même jour qui n’est pas prise en compte ici (il faudra remplacer le < par un <= et rajouter un filter() pour exclure le séjour de la table de gauche des valeurs de celle de droite
Un dernier exemple, trouver les séjours simultanés en 1 ligne :
# la version compacte
vidhosp %>% inner_join(vidhosp, join_by(overlaps(x$entree, x$sortie, y$entree, y$sortie)))
#ou en version plus lisible
vidhosp %>%
inner_join(vidhosp,
join_by(overlaps(x$entree, x$sortie,
y$entree, y$sortie,
bounds = "[]")
)
)
Conclusion
Avec cet article sur les jointures nous finissons l’exploration de la transition des requêtes SQL de type SELECT à proprement parler. Si vous voyez des points manquants n’hésitez pas à demander.
La prochaine fois, nous ferons une petite escapade sur les fonctions() SQL que nous n’avons pas encore vues et leur correspondances en R.
- Peut-être un jour en parlerons-nous « pour le fun » mais ce n’est même pas du R, c’est totalement inutile en usage courant et n’a d’intérêt que si vous voulez interfacer votre code R avec du C++ par exemple. Donc laissons cela de côté pour le moment ! ↩︎