
Dans l’article Le typage des valeurs : les listes simples nous avons fait une introduction aux vecteurs de type list. Cependant, il existe une autre façon d’utiliser ce type.
Création d’un vecteur d’items de liste nommés
Vous avez probablement déjà vu par exemple dans les articles Les fonctions (premier contact) et Les fonctions : paramètres en nombre variable (1ère partie) qu’il est possible d’appeler des fonctions en leur passant des paramètres portant un nom en précédent la valeur d’une étiquette et du signe « = » :
x <- sum(y, na.rm = TRUE)
Dans un tel appel de fonction, il existe un paramètre non nommé dont le contenu sera l’objet y passé en premier à la fonction et un autre spécifiquement nommé « na.rm » contenant la valeur TRUE.
En bien, il est possible de la même façon de nommer certains , tous ou aucun des items d’un vecteur de list.
Pour cela, il suffit au moment de la création de la liste (ou de l’item) de préciser la syntaxe :
> x <- list(a = 1, "2", c = 3)
> x
> x
$a
[1] 1
[[2]]
[1] "2"
$c
[1] 3
On voit alors apparaitre en lieu est place des numéros d’index les noms donnés.
La structure fonctionnelle sous-jacente peut donc alors se décrire ainsi :
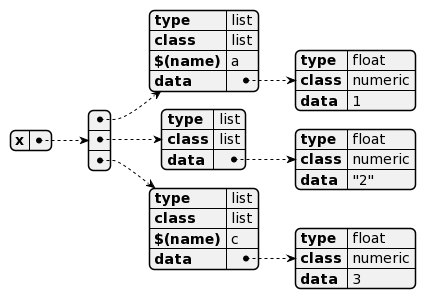
Ces noms sont accessibles via la fonction names() qui retourne un vecteur de type character (avec la chaine « » vide pour les items n’ayant pas de nom):
> names(x)
[1] "a" "" "c"
mais permet aussi de les changer grace à names()<- en lui passant un vecteur de type character :
> names(x)<-c("z","y","x")
> x
$z
[1] 1
$y
[1] 2
$x
[1] 3
Attention, il n’est pas bloquant de répéter ces noms. Ainsi rien n’empêche d’écrire
> x <- list( a = 1, b = 2, a = 3)
> x
$a
[1] 1
$b
[1] 2
$a
[1] 3
cependant cela peut poser problème pour l’accès aux données.
Accéder aux données
Une fois étiquetées, il est possible d’utiliser ces noms pour accéder aux données via différentes méthodes et principalement $ mais [] et [[]] restent utilisables dans leur fonctionnement habituel
Par rapport à la remarque ci-dessus, notez la finesse dans le dernier accès et la différence avec l’usage de $ ou ["..."]: Ils ne retournent que le premier élément trouvé.
> x$a
[1] 1
> x["a"]
$a
[1] 1
> x[1]
$a
[1] 1
> x[names(x)=="a"]
$a
[1] 1
$a
[1] 3
L’accès par $ a une particularité qui peut être un peu déroutante mais présente dans d’autres aspects de R : la reconnaissance partielle. Si le nom exact n’est pas trouvé, s’il existe un nom dont le début correspond et qu’il est unique, le résultat est retourné. Ainsi :
> x <- list(aaa = 1, aab = 2, abc = 3)
> x$a # "a" n'existe pas et en partiel n'est pas unique
NULL
> x$aa # "aa" non plus
NULL
> x$ab # par contre "ab" n'existe pas mais matche "abc" uniquement
[1] 3
attention donc au risque d’effet de bord. Par contre, celui-ci n’existe pas avec la notation x[« ab »] qui retourne une liste d’un élément contenant NULL.
Accéder aux noms
Il est possible d’accéder aux noms comme on l’a vu par names()mais il est aussi possible d’utiliser cette fonction en modification :
> names(x)
[1] "aaa" "aab" "abc"
> names(x)<-c("a","b","c")
> x
$a
[1] 1
$b
[1] 2
$c
[1] 3
# Il est même possible de subsetter :
> names(x)[2]<-c("z")
> names(x)
[1] "a" "z" "c"
Enlever les noms
Pour enlever les noms, il existe la fonction unname(...) qui fait… ce qu’on lui demande. A la différence de names()<- qui travaille « en place », unname() retourne un objet sans ses noms.
Il est aussi possible d’utiliser names() <- NULL qui est cependant moins lisible et lui fait le changement « en place » :
> unname(x)
[[1]]
[1] 1
[[2]]
[1] 2
[[3]]
[1] 3
> names(x) <- NULL
> x
[[1]]
[1] 1
[[2]]
[1] 2
[[3]]
[1] 3
Pour effacer des noms au sein de l’ensemble, attention il ne faut pas attribuer NULL mais « » (la chaine vide) :
> x <- list(a = 1, b = 2, c = 3)
> names(x)[2:3]<-""
> x
$a
[1] 1
[[2]]
[1] 2
[[3]]
[1] 3
En fait, il faut vraiment considérer names(x) comme ce qu’il est, un vecteur de type character.
Attention cependant comme souvent avec R, le diable est dans les détails, selon le mode d’accès avec ou sans subsetting ([]), l’utilisation d’un vecteur de taille différente de la liste échoue avec une erreur ou un warning et donc dans un cas votre programme plante et dans l’autre il continue :
> names(x)[2:3]<-c("a","b","c","d")
Warning message:
In names(x)[2:3] <- c("a", "b", "c", "d") :
number of items to replace is not a multiple of replacement length
> x
$a
[1] 1
$a
[1] 2
$b
[1] 3
> names(x)<-c("a","b","c","d")
Error in names(x) <- c("a", "b", "c", "d") :
'names' attribute [4] must be the same length as the vector [3]
D’autres variantes de list
Outre les listes nommées, il existe :
les alist
Les vecteurs de type alist servent essentiellement à stocker des paramètres de fonction pour les passer lors d’une exécution fonctionnelle (nous le verrons un jour prochain). Elles ont la particularité de ne pas exécuter leurs valeurs à la création et de permettre des items nommés sans valeur :
> alist(a = "1", b = 1 + 1, c =, d = "e")
$a
[1] "1"
$b # Non calculé
1 + 1
$c # Non attribué mais présent
$d
[1] "e"
> list(a = "1", b = 1 + 1, c = , d = "e")
Error in list(a = "1", b = 1 + 1, c = , d = "e") : argument 3 is empty
> list(a = "1", b = 1 + 1, d = "e")
$a
[1] "1"
$b # Calculé
[1] 2
$d
[1] "e"
> alist(a = "1", b = 1 + 1, c =, d = "e")$b
1 + 1 # Non interprété lors de l'accès
> eval(alist(a = "1", b = 1 + 1, c =, d = "e")$b)
[1] 2 # Mais évaluable
> typeof(alist(a = "1", b = 1 + 1, c =, d = "e")$b)
[1] "language"
> class(alist(a = "1", b = 1 + 1, c =, d = "e")$b)
[1] "call"
les pairlist
Les pairlist sont un « entre deux », les valeurs ne sont pas évaluées mais l’item nommé sans valeur n’est pas autorisé.
Je vous laisse faire les essais 😉
Conclusion
Cela termine notre série sur les list pour le moment. La prochaine fois, nous allons retourner faire un peu de PMSI avant d’attaquer les data.frame qui sont le principal type d’objet que nous manipulons.