

Maintenant que nous avons vu comment écrire du code markdown, connaissons les moyens de structuration et les contenus statiques. Il est temps d’incorporer du code R pour afficher nos résultats.
A titre d’illustration, nous allons réutiliser le code utilisé dans la série d’articles Jouons avec les tarifs, la correction et le bonus.
Dans la suite de l’article, nous allons parler de blocs de code. Sachez qu’on les appelle des chunks si vous cherchez des informations sur internet
Personnalisons l’entête.
Nous avons vu dans le 1er article le contenu de l’entête d’un document markdown. Nous devons donc d’abord configurer les champs de l’entête.
Nous allons :
- l’appeler « Etude d’un fichier de tarifs »
- produire une sortie HTML
- utiliser une table des matières
- numéroter les chapitres et sous-chapitres
- insérer notre nom comme auteur
- mettre la date du jour de traitement dans le champ date
- rassembler les paramètres nécessaires dans l’entête (nous les ajouterons au fur et à mesure des besoins en fait)
Réfléchissez à comment écrire l’entête puis regardez ce que je vous propose :
---
title : "Etude d'un fichier de tarifs"
output :
html_document:
toc : yes
number_sections: yes
author : "nom de l'auteur"
date: "`r Sys.Date()`"
params:
---Un bloc de code « amorphe »
Tout d’abord sachez que Markdown utilise ``` (3 accents graves collés aussi appelés backticks) pour identifier le début et la fin d’un bloc de code. Le nom du langage utilisé au sein du bloc suit le premier groupe de backticks.
Markdown connait ainsi nombre de langages de programmation et de description de texte afin d’afficher les sources avec de la coloration syntaxique (comme dans tous les blocs de texte que vous trouvez sur ce site où la couleur des mots change en fonction de leur sens sémantique en R (ou markdown depuis quelques articles). Ainsi si je tape :
```c
/* Ceci est un petit bout de code en C */
#include <stdin.h>
void main(){
printf("Hello World.\n");
}
main();
```
```r
# Ceci est l'équivalent en R
print("Hello World.")
```au sein d’un document markdown, lors de la conversion/compilation, ce code sera mis en couleur même si ce n’est pas du R :

mais, s’agissant d’un bloc « amorphe », le code est juste affiché et pas exécuté. D’ailleurs dans l’éditeur de RStudio, il n’apparait pas sur fond gris (comme les blocs de code que nous allons interpréter) mais sur fond blanc comme du Markdown « standard » :
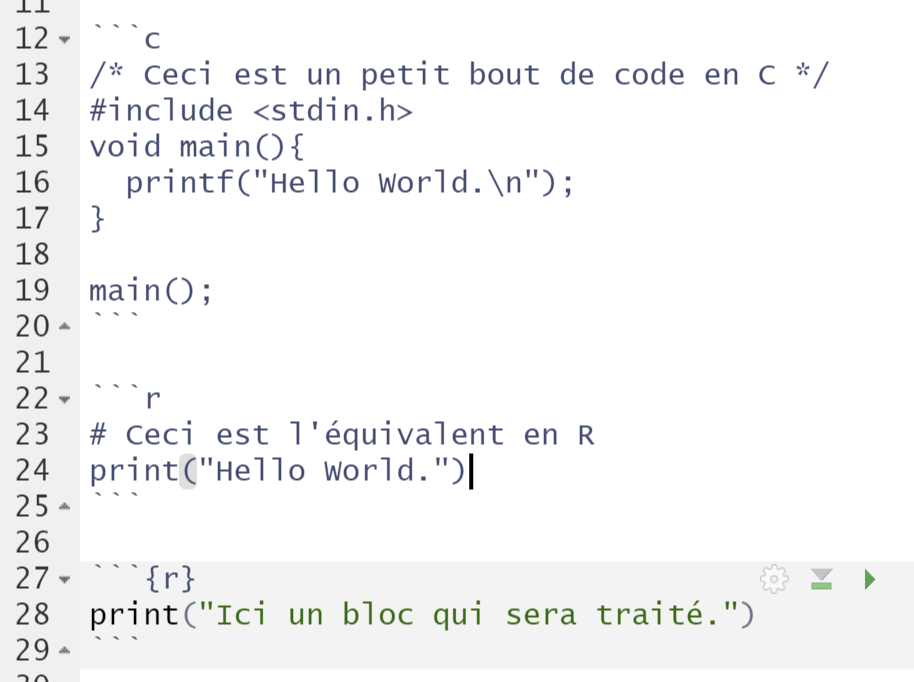
Dans les faits, nous n’utiliserons pas de tels blocs, notre code R nécessitera probablement toujours d’être évalué.
Les blocs interprétés
Un bloc interprété contient du code R (principalement pour nous) mais techniquement tout langage pris en charge par la chaine de production installée sur votre ordinateur est possible. Cela dépasserait cependant largement le sujet de ce site et ne sera pas abordé.
La différence principale est que le nom du langage derrière les ``` est à mettre entre accolades { }. La structure totale de cette première ligne devient alors :
```{nom-du-langage nom-du-bloc, options, ...}
Le nom-du-langage (r pour nous) est obligatoire, tous les autres paramètres sont facultatifs.
Le nom-du-bloc est facultatif mais s’il est utilisé, il doit être unique dans le document.
Les options sont des couples étiquette=valeur. Par ailleurs, si le bloc n’est pas nommé, la première option suit directement le nom du langage sans la virgule.
Cet article étant le premier, nous n’allons aborder que les 3 options principales et 1 secondaire:
L’option include
- si réglée à TRUE (valeur par défaut), le bloc sera traité selon les valeurs des 3 options suivantes (et des autres que nous ne verrons pas maintenant) et le résultat affiché.
- si réglée à FALSE, le bloc sera totalement ignoré
L’option echo
- si réglée à TRUE (valeur par défaut), le code source du bloc sera présent dans le document final.
- si réglée à FALSE, le code source ne sera pas imprimé, seul éventuellement le résultat
L’option eval
- si réglée à TRUE (valeur par défaut), le code du bloc sera évalué.
- si réglée à FALSE, le résultat ne sera pas imprimé
L’option results
Cette option attend une chaine de caractères donnant l’indication au moteur quant à son mode de présentation des résultats. Parmi les valeurs possibles les principales sont :
"markup": (par défaut) Le code est « embelli » à la markdown et ne sera pas interprété comme du markdown"asis": (« as is » = « tel quel » en anglais) Le code produit sera interprété directement comme du markdown à l’étape suivante
Pour résumer les options principales
| include = | echo = | eval = | Résultat |
| TRUE | TRUE | TRUE | Le code sera évalué, affiché en sortie, ainsi que le résultat |
| TRUE | TRUE | FALSE | Le code n’est pas évalué mais est affiché, il n’existe pas de résultat (ce mode est équivalent à un bloc « amorphe » ci-dessus) |
| TRUE | FALSE | TRUE | Le code est évalué, pas affiché et le résultat affiché |
| TRUE | FALSE | FALSE | Le bloc de code est totalement ignoré |
| FALSE | TRUE | TRUE | Le bloc de code est évalué sans rien en sortie |
| FALSE | TRUE | FALSE | Le bloc de code est totalement ignoré |
| FALSE | FALSE | TRUE | Le bloc de code est évalué sans rien en sortie |
| FALSE | FALSE | FALSE | Le bloc de code est totalement ignoré |
Notez que certaines conditions entrainent une absence totale de sortie et/ou de prise en compte ce qui peut avoir des impacts et peut même provoquer des bugs dans votre code plus bas. Par exemple le code ci-dessous ne compilera pas car le bloc1 n’est pas évalué donc a ne prend pas la valeur 1 et le print() dans le bloc2 cherche à imprimer une valeur non initialisée précédemment.
```{r bloc1, eval=FALSE}
a<- 1
```
```{r bloc2}
print(a)
```Le résultat …

Enfin sachez qu’il est tout à fait possible de mettre dans les valeurs des options de chaque bloc, un résultat calculé c’est à dire de conditionner l’aspect ou l’exécution d’un bloc au résultat d’une valeur définie ou calculée précédemment. Dans le code ci dessous, si a est défini, bloc2 est exécuté, si on commente la ligne a <- 1, bloc2 ne s’exécutera pas.
```{r bloc1, eval=FALSE}
a <- 1
```
```{r bloc2, eval = hasName(environment(),"a"), include = hasName(environment(),"a")}
print(a)
```Le réglage des options par défaut
Toutes les options de bloc sont réglables au niveau du document tout entier via l’appel de la fonction knitr::opts_chunk$set(<liste des options>). Ces nouveaux réglages deviennent uniquement valides pour la suite du document d’où l’intérêt de l’exécuter au début de celui-ci. Il faut que cette commande soit à l’intérieur d’un bloc de code évalué bien sûr.
Bien sûr, rien n’empêche de régler les options d’un bloc en particulier ensuite.
L’enchainement des blocs
Chaque bloc est exécuté dans l’ordre où il est écrit et dans le même environnement pour tout le document. Cela veut dire qu’une valeur initialisée dans un bloc précédent, évalué, est disponible dans les blocs suivants.
Tous les blocs forment donc le même programme R, ils sont juste intercalés entre des portions en markdown pour la présentation statique.
Si on enlève le eval = FALSE de l’exemple précédent, on obtient une sortie à l’écran :
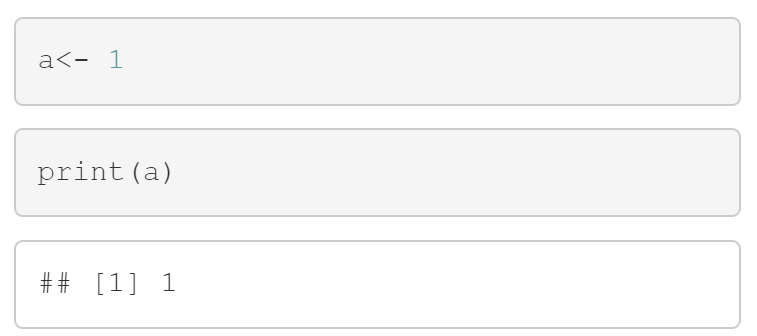
1 est attribué à a dans le bloc1 et imprimé via print() dans le bloc2.
Notez que le print() est en réalité inutile, c’est la méthode de sortie par défaut de R dans un chunk. Ecrire a isolément sur une ligne revient au même. Je l’ai précisé uniquement pour la lisibilité de l’action réalisée.
Par ailleurs, à la différence par exemple du PHP, il n’est pas possible d’insérer du markdown à l’intérieur d’un bloc de code. Chaque bloc de code doit être syntaxiquement correct en lui-même. Par exemple il n’est pas possible de faire une boucle dont le début serait dans un bloc et la fin dans un autre.
Les bonnes pratiques
Les éléments de configuration dans le bloc params: de l’entête
Nous avons déjà vu qu’il faut au maximum mettre les paramètres accessibles à l’utilisateur dans params:
En reprenant le contenu de l’article Jouons avec les tarifs, on va rajouter dans l’entête les éléments configurateurs ainsi :
---
<...>
params:
motifFichiersGHS: "~/R/%ANNEE%/ghs_pub.csv"
motifFichiersRGHM: "~/R/2022/regroupements_racinesghm.xlsx"
statut: "public"
motifFichiersGHMINFO: "~/R/2022/GHMINFO_"
ANNEE_R: 2023
ANNEE_N: 2024
fichierRSA: "~/R/XXXXXXXXX.2023.12.rsa"
<...>
---A vous de les personnaliser pour qu’ils correspondent à votre rangement.
Un bloc setup
L’autre bonne pratique est de commencer le document par un bloc de mise en place (setup en anglais) s’évaluant mais ne générant pas de sortie. On y met l’import des librairies, le « sourçage » de fichiers de code R externe, les constantes, les définitions de fonctions nécessaires dans le cadre du document. (Ici l’ensemble du code de l’article Jouons avec les tarifs, seule la partie sur le chargement de données (la 2) à été adaptée pour utiliser les params:).
```{r setup,include = FALSE, eval = TRUE}
###########################################################
# Réglage du comportement par défaut des blocs de code
# Le code est :
# - pas affiché (echo)
# - évalué (eval)
# - sans affichage des erreurs non bloquantes (warnings)
knitr::opts_chunk$set(echo = FALSE, eval = TRUE, warning = FALSE)
###########################################################
#Chargement des librairies
library(dplyr) # pour toute la logique relationnelle
library(tidyr) # pour certaines sélections de colonnes
library(readr) # pour lire le RSA et les csv
library(readxl) # pour lire le fichier excel du regroupement des GHM
library(lubridate) # pour la manipulation de dates
library(ggplot2) # pour les graphiques
###########################################################
# Chargement des données passées en paramètres dans les champs correspondants
# On pourrait utiliser directement params$... en lieu et place
# mais vu que notre code existe déjà, évitons de le retoucher
motifFichiersGHS <- params$motifFichiersGHS
motifFichiersRGHM <- params$motifFichiersRGHM
statut <- params$statut
motifFichiersGHMINFO <- params$motifFichiersGHMINFO
ANNEE_R <- params$ANNEE_R
ANNEE_N <- params$ANNEE_N
fichierRSA <- params$fichierRSA
##########################################################
# Fonctions nécessaires
# Fonction de chargement de RSA
chargeRSA <- function(fichierRSA) {
read_fwf(
file = fichierRSA,
col_positions = fwf_cols(
NRSA = c(13,22),
GHMIN = c(31, 36),
RGHMIN = c(31, 35),
SEVIN = c(36, 36),
GHMOUT = c(42, 47),
RGHMOUT = c(42, 46),
SEVOUT = c(47, 47),
AGEA = c(53, 55),
AGEJ = c(56, 58),
SEXE = c(59, 59),
MOIS = c(62, 63),
ANNEE = c(64, 67),
GHS = c(96, 99),
DS = c(71, 74),
TOPUHCD = c(111, 111),
MINORE = c(112, 112),
RAAC = c(199, 199),
DP = c(212, 217),
DR = c(218, 223)
),
col_types = list(
col_character(),
col_character(),
col_character(),
col_character(),
col_character(),
col_character(),
col_character(),
col_number(),
col_number(),
col_character(),
col_number(),
col_number(),
col_number(),
col_number(),
col_character(),
col_character(),
col_character()
)
)
}
# Génération du chemin selon l'année
genereChemin = function(fp, annees){
lapply(annees, function(x){sub("%ANNEE%",x, fp)}) %>% as.character
}
# Fonction de chargement des GHSs
chargeGHSs <- function(rsa,fp,simplify = FALSE){
t <- read_csv2(genereChemin(fp,seq(min(rsa$ANNEE)-1,max(rsa$ANNEE))),
col_types = list(
col_number(),
col_character(),
col_character(),
col_character(),
col_character(),
col_number(),
col_number(),
col_number(),
col_number(),
col_number(),
col_number(),
col_date(format="%d/%M/%Y")),
col_names = c("GHS",
"CMD",
"DCS",
"GHM",
"LIB",
"BB",
"BH",
"GHSPRIX",
"FORFAIT_EXB",
"EXBPRIX",
"EXHPRIX",
"DEFFET"),
skip = 1 # On saute une ligne, vu qu'on définit directement les noms de colonnes
)
if (simplify == TRUE){
t <- t %>% group_by(GHS,DEFFET) %>% summarise(
CMD = first(CMD),
DCS = first(DCS),
GHM = first(GHM),
LIB = first(LIB),
BB = first(BB),
BH = first(BH),
GHSPRIX = first(GHSPRIX),
FORFAIT_EXB = first(FORFAIT_EXB),
EXBPRIX = first(EXBPRIX),
EXHPRIX = first(EXHPRIX),
DEFFET = first(DEFFET)
)
}
t %>% mutate(ANNEE = as.character(year(DEFFET)))
}
# Fonction de valorisation unitaire
valorise <- function(ghs, ds, bb, bh, ghsprix, forfait_exb = 0, exb, exh){
dna = !is.na(ghsprix)
dexb= dna & (ds < bb) & (forfait_exb == 0)
dexh = dna & (ds > bh)
dforfait = dna & (ds < bb) & (forfait_exb >= 0)
dghs = dna & (ds >= bb) & (ds <= bh)
x<-double()
x[!dna] <- NA
x[dghs] <- ghsprix[dghs]
x[dforfait] <- ghsprix[dforfait] - forfait_exb[dforfait]
x[dexb] <- ghsprix[dexb] + (bb[dexb] - ds[dexb]) * exb[dexb]
x[dexh] <- ghsprix[dexh] + (ds[dexh] - bh[dexh]) * exh[dexh]
x
}
# Fonction de valorisation en masse
valorise.ghs_df <- function (x, ghss, ghs_col = "GHS", ds_col = "DS",
annee_col = NA, out_col = "valo",
FUN = "valorise"){
if (out_col %in% names(x))
stop("la colonne de sortie `", out_col, "`` existe déjà.")
if (!(ghs_col %in% names(x)))
stop("la colonne du GHS `", ghs_col, "` est absente du jeu source.")
if (!(ds_col %in% names(x)))
stop("la colonne de durée de séjours `", ds_col, "` est absente du jeu source.")
if(is.na(annee_col)) {
y <- x %>% mutate(anneeValo=as.character(ifelse(MOIS<3,ANNEE-1,ANNEE)))
annee_col <- "anneeValo"
} else {
if (annee_col %in% names(x))
y <- x
else {
y <- x %>% mutate(anneeValo=as.character(ifelse(MOIS<3,ANNEE-1,ANNEE)))
message("La colonne \"",
annee_col,
"\" correspondant au paramètre `annee_col` n'a pas été trouvée. `anneeValo` a été utilisée à sa place en interne.")
annee_col <- "anneeValo"
}
}
y <- y%>% select(all_of(c(ghs_col,ds_col,
annee_col)))
y <- y %>% left_join(ghss,by=c(setNames(c("GHS", "ANNEE"),c(ghs_col,annee_col))))
x[,out_col] <- do.call(FUN, args = list(NA,
y[, ds_col],
y[, "BB"],
y[, "BH"],
y[, "GHSPRIX"],
y[, "FORFAIT_EXB"],
y[, "EXBPRIX"],
y[, "EXHPRIX"]))
x
}
###########################################################
# Création des tables de base
RSA <- chargeRSA(fichierRSA)
GHS_N <- read_csv2(genereChemin(motifFichiersGHS,ANNEE_N),
col_types = list(
col_number(),
col_character(),
col_character(),
col_character(),
col_character(),
col_number(),
col_number(),
col_number(),
col_number(),
col_number(),
col_number(),
col_date(format="%d/%M/%Y")),
col_names = c("GHS",
"CMD",
"DCS",
"GHM",
"LIB",
"BB",
"BH",
"GHSPRIX",
"FORFAIT_EXB",
"EXBPRIX",
"EXHPRIX",
"DEFFET"),
skip = 1) %>%
mutate(ANNEE = as.character(year(DEFFET)))
GHS_R <- read_csv2(genereChemin(motifFichiersGHS,ANNEE_R),
col_types = list(
col_number(),
col_character(),
col_character(),
col_character(),
col_character(),
col_number(),
col_number(),
col_number(),
col_number(),
col_number(),
col_number(),
col_date(format="%d/%M/%Y")),
col_names = c("GHS",
"CMD",
"DCS",
"GHM",
"LIB",
"BB",
"BH",
"GHSPRIX",
"FORFAIT_EXB",
"EXBPRIX",
"EXHPRIX",
"DEFFET"),
skip = 1) %>%
mutate(ANNEE = as.character(year(DEFFET)))
RGHM <- read_excel(motifFichiersRGHM,
col_names = c("RGHM", "LIB", "ASO",
"DA", "DA-LIB",
"GP", "GP-LIB",
"GA", "GA-LIB",
"DA-GP", "DA-GP-GA"),
skip = 1)
```Vous voyez que comme cela ce bloc est très gros et risque de gêner l’écriture du reste du code. De plus ce code est réutilisable. Il conviendrait plutôt d’utiliser un fichier R externe et l’inclure via un source(). Nous aurions aussi pu faire plusieurs blocs par exemple . Je ne l’ai pas fait uniquement dans le cadre de cet article pour garder un document unique.
Nous pouvons maintenant commencer à écrire notre document et les éléments de traitement.
Les différents blocs
Vous pouvez désormais insérer du code markdown ou des blocs de code afin d’obtenir le document comme vous l’espérez.
Nous avons vu les blocs « individualisés », introduite par 3 backticks, qui forment en quelque sorte un paragraphe (un saut de ligne doit être inséré au dessus et au dessous) mais il est aussi possible d’insérer du code qui sera évalué au sein d’une ligne (ce qu’on appelle inline, l’équivalent d’un <span> en html). Pour cela il suffit de mettre 1 seul backtick suivi du langage pour ouvrir et 1 seul backtick pour finir. Il n’y a alors pas de saut.
Par exemple, le code Rmarkdown :
# Etude de l'évolution tarifaire entre les années `r ANNEE_R` et `r ANNEE_N`. {-}
Donnera une sortie ainsi :

L’aspect des données R
Les données issues de l’évaluation d’un code R dépendront de leur type. Ainsi un graphique apparaitra en tant qu’image (vectorielle) tandis qu’un data.frame ou dérivé apparaitra sous une forme de tableau et le texte selon la valeur de l’option results=.
Les tableaux
Par défaut, il existe plusieurs type de présentation des données en tableau :
Le type « paged »
C’est le type par défaut, adapté à la consultation via une page HTML :
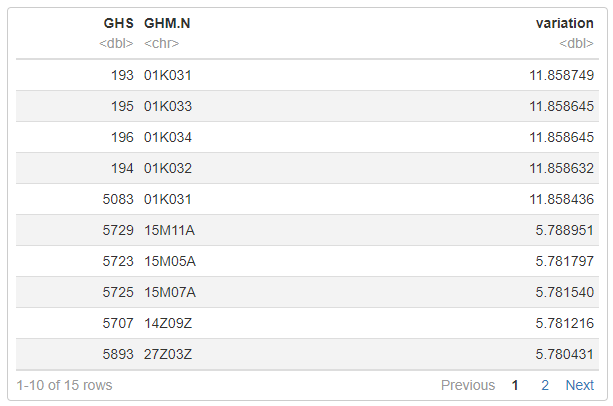
Le type « kable »
Il affiche une table statique contenant toutes les lignes. La présentation est plus adaptée à la production de documents « statiques » type PDF ou de rapports nécessitant une vision exhaustive des lignes
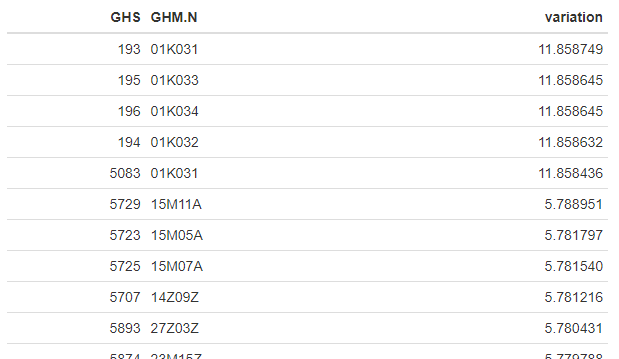
Un package kableExtra, vient compléter pour personnaliser l’aspect. Nous aborderons le format kable une autre fois car à lui seul il peut nécessiter un ou plusieurs articles. Sachez juste que utilise kable() avec les options par défaut (donc sans passer de paramètre) est largement suffisant pour débuter.
Le type « tibble »
Ce type produit une sortie brute en mode texte des données :
Autant dire qu’il a peu d’intérêt pour sortir des rapports pour des non-techniciens/non-informaticiens…
Les graphiques
Tout élément graphique généré par du code R sera inclus dans le document final à sa place dans le flux de sortie. Cela veut dire que faire : (pour les curieux c’est le code d’exemple habituel de ggplot qui représente la consommation en fonction de la cylindrée par classe de voiture)
# Exemple ggplot2 {-}
```{r}
library(ggplot2)
ggplot(mpg, aes(displ, hwy, colour = class)) +
geom_point()
```Insère directement le graphique résultat dans la page :
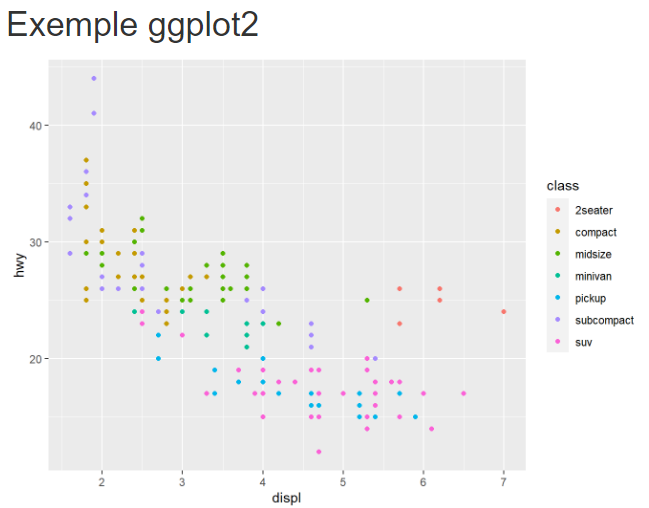
Il est possible de modifier l’apparence des graphiques et images au sein d’un chunk ou de tout le document en réglant des options mais nous les verrons une prochaine fois.
Le fichier résultat
Le résultat en mode HTML est par défaut une page unique où les éléments graphiques générés par le code R sont incluses, idem pour le PDF qui est un format qui encapsule tous les éléments nécessaires. Cela a un intérêt indéniable pour la portabilité : vous récupérez votre page HTML ou document PDF et pouvez les joindre tels quels en attachement dans un mail par exemple et vos correspondants pourront les lire sans avoir besoin de ressource externe.
Vous les trouverez dans votre répertoire de travail, juste à côté de vos fichiers sources.
Attention cependant, si vous utiliser Markdown pour insérer des images, celles-ci ne seront pas incluses dans le source HTML mais seront accédées par le navigateur lors du rendu de la page. Dans ce cas, il peut y avoir des problèmes de firewall ou d’accès au lieu de stockage par exemple.
Conclusion
Avec les éléments vu dans cet article et les précédents vous devriez être capable d’écrire un premier jet de document Rmarkdown pour illustrer le sujet des tarifs.