Dans l’article précédent nous avons commencé à décortiquer la façon dont R peut être utilisé pour faire des requêtes simples en remplacement de SQL grâce à la librairie dplyr. Nous continuons aujourd’hui avec l’agrégation et le fenêtrage.
L’article s’attend à ce que vous ayez des bases de SQL. Cependant vous pouvez le lire uniquement pour l’apprentissage de dplyr.
L’agrégation, qu’est-ce que c’est ?
L‘agregation de données c’est l’ensemble des processus permettant depuis des données brutes d’obtenir une vision simplifiée en réduisant le nombre de variables et de lignes. On parle aussi de regroupement.
Par exemple décrire des données numériques en spécifiant leur moyenne est une agrégation : nous partons de n données et par un calcul mathématique nous isolons un trait qui les représente et qui n’est plus qu’une valeur unique.
En SQL, les fonctions d’agrégation nécessitent la spécification d’un ou plusieurs champs qui seront utilisés pour segmenter la totalité des données.
Cette segmentation se fait au travers du mot clé accessoire SQL GROUP BY en premier lieu. Ce mot clé est suivi d’une liste de champs servant au regroupement. La présence de GROUP BY modifie le fonctionnement de SELECT qui doit au minimum contenir les mêmes champs que le GROUP BY auxquels on peut ajouter des champs résultats d’appel de fonctions d’agrégation. Ajouter des champs source non présents dans le GROUP BY entrainera une erreur d’interprétation.
-- Compter le nombre de lignes de RSA dans chaque GHM
SELECT ghm, COUNT(id)
FROM rsa
GROUP BY ghm;Dans le code ci-dessus , GROUP BY définit le critère de l’agrégation tandis que COUNT() est une fonction d’agrégation (attention c’est encore un faux-ami, nous verrons cela plus loin).
En plus du GROUP BY, il est possible de rajouter une clause de filtre grace à HAVING.
Pour être simple :
WHEREva filtrer le jeu de données initiales c’est à dire va sélectionner les éléments de la table source.HAVINGva filtrer directement sur le résultat de l’agrégation.
-- Compter le nombre de lignes de RSS dans [chaque GHM ayant plus de 10 occurences] chez les patients de plus de 75 ans
SELECT ghm, COUNT(id)
FROM rss
WHERE age >= 75
GROUP BY ghm
HAVING COUNT(id)>= 10;Comment traduisons nous tout ça en R ?
Avec dplyr, il existe une fonction group_by() qui ressemble assez à celle en SQL sauf que, comme il existe mutate() (qui fait les calculs) en supplément de select() (qui fait les sélections pures), elle a besoin d’une « âme soeur » pour faire les calculs d’agrégation. Il s’agit de la fonction summarise() ou summarize() (c’est un mot qui ne s’écrit pas de la même façon selon le côté de l’Atlantique où on se trouve, donc dplyr fournit les 2 versions au fonctionnement strictement identitque).
Note premier code SQL ci-dessus s’écrit en R ainsi :
rss %>%
group_by(ghm) %>%
summarise(nombre = n())Par défaut, dplyr intègre toujours les champs utilisés dans le group_by() dans le jeu résultat, pas besoin de les spécifier via un select().
Et notre second exemple donne :
rss %>%
filter(age >= 75) %>%
group_by(ghm) %>%
summarise(nombre = n()) %>%
filter(nombre >= 10)le HAVING, qui n’est qu’un filtre comme un autre au final a été remplacé par un second filter() (mais vu sa position, il travaille sur le jeu de données déjà transformé par l’ensemble group_by()/summarise() ).
Cette façon d’écrire gagne tout son sens si vous pensez pipeline et ce qui est bien par rapport au SQL, c’est qu’on peut continuer la chaîne à l’infini !
Il est possible de grouper par plusieurs champs en mettant plusieurs noms dans le group_by() :
# On groupe par ghm et par sexe :
rss %>%
group_by(ghm, sexe) %>%
summarise(nombre = n())Il existe une autre méthode de groupage mais qui s’éloigne de la ressemblance avec SQL et qui est un peu moins lisible, je ne l’évoquerai pas ici.
Le dégroupage
La remontée de niveau « automatique »
Arrêtons-nous quelques minutes car il y a une finesse à comprendre :
group_by() est une fonction qui a son sens utilisée seule car elle transforme une table en table groupée (grouped_df)
> rss %>% group_by(nda) %>% class()
[1] "grouped_df" "tbl_df" "tbl" "data.frame"… et c’est tout, tout est caché à ce stade.
Ces 2 types de tables sont similaires quand on les explore à une différence près se trouvant dans l’entête :
> rss
# A tibble: 28,517 × 52
(...)
> rss %>% group_by(ghm, sexe)
# A tibble: 28,517 × 52
# Groups: ghm, sexe [1,601]
(...)En gros le group_by() a préparé le terrain pour customiser le fonctionnement d’autres verbes mais n’a pas d’action sur les données elles-mêmes. L’entête nous précise le nombre de groupes retrouvés. Je ne rentrerai pas dans les détails internes.
Voyons maintenant ce qui se passe lors qu’on exécute un summarise() à la suite :
> rss %>% group_by(ghm, sexe) %>% summarise(n = n())
`summarise()` has grouped output by 'ghm'. You can override using the `.groups` argument.
# A tibble: 1,601 × 3
# Groups: ghm[1,005]
(...)Le fait d’utiliser summarise() a réduit le niveau de regroupement qui était « ghm et sexe » en « ghm seulement ». D’ici on pourrait continuer le traitement directement sur le regroupement toujours présent si c’était nécessaire.
Dans le cas d’un regroupement à un seul champ, le résultat de la remontée automatique est directement une table non groupée.
Enfin, le paramètre .groups="drop" passé dans le summarise() permet de dégrouper la table dans le même temps. A titre personnel, je trouve cela moins lisible que la fonction suivante mais permet de ne pas afficher le message d’information ce qui peut être plus agréable au sein d’un programme.
Le dégroupage total : ungroup()
A tout moment, il est possible de repasser d’une table groupée à une table standard via la commande ungroup() sans paramètre. Si vous passez des noms de champs en paramètres, cela spécifie ceux qui vont être retirés du regroupement.
C’est important si vous voulez supprimer des colonnes qui sont des clés de regroupement via un select() car c’est interdit (un peu comme en SQL où les colonnes de regroupement DOIVENT être dans le SELECT) mais ne génère pas d’erreur (juste un warning) : les colonnes concernées sont tout simplement rerajoutées au jeu de sortie et votre demande ignorée.
Typiquement c’est lorsqu’on calcule un résultat se basant sur les champs de regroupement après le summarise() :
> rss %>%
filter(age >= 75) %>%
group_by(ghm, sexe) %>%
summarise(nombre = n()) %>%
mutate(ghm_sexe = paste(gmh, sexe)) %>%
select(-ghm, -sexe)
`summarise()` has grouped output by 'ghm'. You can override using the `.groups` argument.
Adding missing grouping variables: `ghm`
# A tibble: 1,601 × 3
# Groups: ghm[1,005]
ghm n ghm_sexe
<chr> <int> <chr>
(...) Dans le cas ci-dessus, on a calculé un champ basé sur les clés de regroupement, il n’est donc plus très pertinent de les conserver ; sexe a été supprimé du regroupement par le summarise() mais il persiste ghm. Le select() qui tente de les supprimer est contrecarré pour ghm et le résultat final contient donc le champ. L’usage de ungroup() nous sauve la mise :
> rss %>%
filter(age >= 75) %>%
group_by(ghm, sexe) %>%
summarise(nombre = n()) %>%
mutate(ghm_sexe = paste(gmh, sexe)) %>%
ungroup %>% # <--- ICI le dégroupage total
select(-ghm, -sexe)
`summarise()` has grouped output by 'GHMC'. You can override using the `.groups` argument.
# A tibble: 1,601 × 2
n ghm_sexe
<int> <chr>
(...)
# les champs ghm et sexe ont tous les 2 pu être supprimésEt comme dit plus haut, il est aussi possible d’utiliser .groups = "drop" dans le summarise().
Le regroupage
A tout moment il est possible de réappliquer un autre group_by().
Selon la valeur du paramètre que vous passerez à .add= (FALSE par défaut), vous remplacerez (dans le cas de .add = FALSE) ou complèterez (si vous passez .add = TRUE) le regroupement déjà existant :
> rssg1 <- rss %>% group_by(ghm)
# A tibble: 28,517 × 52
# Groups: ghm [1,005]
(...)
> rssg1 %>% group_by(sexe, .add = TRUE)
# A tibble: 28,517 × 52
# Groups: ghm, sexe [1,601]
(...)
> rssg1 %>% group_by(sexe, .add = FALSE)
# A tibble: 28,517 × 52
# Groups: sexe [2]
(...)La partition
En SQL, il existe une autre façon de réaliser un traitement par groupes ou fenêtres, il s’agit de la partition. Celle-ci s’écrit :
SELECT ghm,
COUNT(id) OVER(PARTITION BY sexe) AS n
FROM rss;Cette requête se lit « prend la table rss, garde le champ ghm, calcule le décompte sur le groupe/la fenêtre selon la valeur de sexe et met le résultat dans le nouveau champ n sur chaque ligne du groupe/de la fenêtre ». En écrivant cela, chaque enregistrement du jeu destination va posséder un champ n supplémentaire sans qu’il n’y ait de regroupement de lignes.
En R, c’est possible et ce n’est qu’un usage différent de ce que nous avons vu plus haut. La où summarise() réalise l’agrégation, nous connaissons déjà une fonction qui sert à créer des nouvelles colonnes : mutate(). Pour émuler une partition, il suffit donc juste de faire suivre le group_by() d’un mutate() :
#Le code ci-dessus s'écrit :
rss %>% group_by(sexe) %>%
mutate(n = n()) %>%
select(ghm, n)… tout simplement…
Attention cependant, la partition en dplyr ne gère pas directement les fenêtres glissantes :
-- portion de code SQL pour calculer la somme glissante sur 7 jours
(...)
sum(nombre) OVER(
ORDER BY date
ROWS BETWEEN 6 PRECEDING AND CURRENT ROW
)En R on écrirait :
df <- df %>%
arrange(date) %>%
mutate(sum_7days = sapply(seq_along(nombre), function(i) {
start <- max(1, i - 6) # 6 lignes précédentes
sum(nombre[start:i])
}))
#ou bien :
df <- df %>%
arrange(date) %>%
mutate(
csum = cumsum(nombre),
sum_7days = csum - lag(csum, 7, default = 0)
) %>%
select(-csum)Par contre over() existe avec dbplyr quand on veut interroger une base en SQL « caché » (on le verra plus tard dans un autre article spécifique).
Les fonctions de calcul de regroupement ou de fenêtres
La différence principale entre ces deux types de fonctions est que les fonctions d’agrégation sont constantes au sein d’un groupe alors que les fonctions de fenêtres varient selon la ligne où elles sont calculées.
Typiquement une fonction d’agrégation peut être appelée dans une partition (et renverra la même valeur au sein de l’ensemble), mais on comprend aisément que l’inverse ne peut pas être vrai.
Les fonctions d’agrégation
Une fonction d’agrégation est une fonction qui calcule un résumé d’un sous-ensemble (défini par GROUP BY ... ou OVER(PARTITION BY ...) en SQL ou par un group_by() en R).
Il existe un parallèle entre SQL et R pour les fonctions standards avec quelques faux amis en passant :
| SQL | R | Commentaire |
|---|---|---|
| COUNT(…) | n() | le nombre d’enregistrements dans le regroupement ou la partition |
| COUNT(DISTINCT …) | n_distinct() | idem mais les combinaisons uniques |
| AVG(…) | mean(…) | la moyenne du regroupement ou de la partition |
| MEDIAN(…) * | median(…) | la médiane * Plusieurs SGBD n’ont pas cette fonction et nécessitent de passer par un prétraitement ou des requêtes imbriquées |
| STDEV() * | sd(…) | la « déviation standard » anglicisme correspondant à l’écart-type * gros polymorphisme entre SGBD |
| * | IQR(…) | l' »InterQuartile Range » ou écart interquartile en français * souvent pas d’équivalent direct |
| * | mad(…) | l’écart absolu médian * souvent pas d’équivalent direct |
| SUM(…) | sum(…) | la somme |
| MIN(…) | min(…) | la minima |
| MAX(…) | max(…) | la maxima |
| FIRST(…) | first(…) | la première valeur |
| LAST(…) | last(…) | la dernière valeur |
| SUM(CASE WHEN … THEN 1 ELSE 0 END) > 0 | any(…) | au moins 1 valeur du regroupement est vraie |
| SUM(CASE WHEN NOT cond THEN 1 ELSE 0 END) = 0 | all(…) | toutes les valeurs sont vraies |
Ce ne sont là que les fonctions les plus classiques, et bien sûr il est souvent possible d’en écrire d’autres en cas de besoin.
La quasitotalité de ces fonctions pour la partie en R nécessitent de gérer différemment le cas particulier des valeurs NA (équivalent de NULL en SQL), nous l’avons évoqué dans l’article précédent. Cela se fait en rajoutant le paramètre na.rm=TRUE afin que les fonctions les ignorent si cela est pertinent pour avoir le même comportement qu’en SQL.
Dans le cas any() et all(), il est aussi possible, en SQL, de passer par des sous-requêtes avec EXISTS mais on dépasse le but de notre article qui est de passer à R et pas d’approfondir en SQL.
Les fonctions de fenêtrage
Outre ces fonctions de regroupement, on trouve donc aussi les fonctions de fenêtrage qui permettent de se référer à d’autres valeurs de la fenêtre définie par une PARTITION (et uniquement au sein de celle-ci). Ces fonctions n’ont pas de sens dans une agrégation par GROUP BY). En R, group_by() remplaçant les 2 mots-clés SQL, la différence disparait.
| SQL | R | Commentaire |
|---|---|---|
| ROW_NUMBER() | row_number() | |
| RANK() OVER(ORDER BY …) | min_rank(…) | le ORDER BY est nécessaire pour préciser la colonne et la trier |
| DENSE RANK() OVER(ORDER BY …) | dense_rank(…) | |
| NTILE() OVER(ORDER BY …) | ntile(…) | |
| PERCENT_RANK() OVER(ORDER BY …) | percent_rank(…) | |
| CUME_DIST() OVER(ORDER BY …) | cume_dist(…) | |
| LAG(…) / LEAD(…) | lag(…) / lead(…) | |
| * | cumsum() et autres fonctions cumulatives similaires | Somme accumulée * pas d’équivalent direct ou polymorphisme selon SGBD |
…etc.
En R, n’importe quelle fonction travaillant sur un ou plusieurs vecteurs peut être utilisée dans un group_by() %>% summarise() ou %>% mutate() pour faire un traitement sur les sous-groupes faisant exploser les possibilités. Nous y reviendrons dans un autre article.
SELECT DISTINCT et SELECT DISTINCTROW
J’ai associé ici ce vocable car il agit in fine un peu comme un regroupement.
En R, cela s’écrit… distinct() en précisant les colonnes à tester.
Il est aussi possible de régler le paramètre .keep_all= sur TRUE pour que toutes les colonnes soient conservées. Dans ce cas c’est la première valeur rencontrée de chaque champ qui est gardée.
# SQL : SELECT DISTINCT nda, ghm FROM rss;
# R/dplyr :
rss %>% distinct(nda, ghm)
# va garder le champ nda et le champ ghm qui sont constants
# au sein d'un même RSS. Il n'y aura pas de doublon
# SQL : SELECT DISTINCT ON (nda, ghm) *
# FROM rss;
# Attention, uniquement disponible dans certains SGBD
# R/dplyr :
rss %>% distinct(nda, ghm, .keep_all = TRUE)
# va garder tous les champs avec le contenu du 1er RUM
# Conceptuellement c'est l'équivalent de
rss %>% group_by(NDA) %>% summarise(across(everything(),first))
# mais le temps de traitement est sans commune mesure,
# 1400x plus long dans le cas du group_by() !Comme d’habitude on peut utiliser les mêmes fonctions de choix de colonnes que dans un select() (voir l’article précédent)
Les versions courtes
Il existe quelques fonctions permettant de raccourcir certaines actions courantes. C’est à dire mettre moins de verbes dans le pipeline ou moins de paramètres dans les ().
(Ne pas) compter les enregistrements d’un groupe : nrow()
nrow() n’est pas une fonction de regroupement (elle ne renvoit pas une table mais une valeur isolée, un vecteur de longueur 1) ni même une fonction spécifique à dplyr (c’est une fonction de R base):
> rss %>% nrow()
[1] 28517Si vous l’utilisez au sein d’un group_by(), nrow() ne respecte pas le regroupement et renvoie TOUJOURS la taille de la table entière, cela peut avoir un intérêt pour faire des pourcentages d’occurrence par exemple :
rss %>% group_by(sexe) %>% summarise(pct = n() / nrow(.))
# notez le "." qui veut dire "l'objet source" (donc rss)
nrow() n’a pas été faite pour travailler spécifiquement avec dplyr, c’est pourquoi il faut lui passer « . » comme paramètre. Cependant, elle est souvent plus adaptée pour récupérer directement la taille de table pour l’utiliser dans un traitement ou l’afficher.
Compter/pondérer par sous-groupe : count(), add_count() (, tally(), add_tally())
Plutôt que de faire group_by(<criteres>) %>% summarise(n=n()) on peut directement utiliser count( :<criteres>)
rss %>% count(ghm, sexe)
# c'est équivalent à
rss %>% group_by(ghm, sexe) %>% count()
# ou encore
rss %>% group_by(ghm, sexe) %>% summarise(n = n())
A la différence de nrow(), le résultat est une table contenant le regroupement et pas un nombre.
Il est possible de préciser le nom de la colonne résultat (par défaut « n ») avec le paramètre name= et on peut demander aussi de classer par valeur produite décroissante avec sort = TRUE (par ordre croissant n’est pas prévu, il faut passer par la version complète).
Il est aussi possible de passer le paramètre wt= (weight soit poids en français). C’est ce qu’on appelle un champ de pondération. On peut écrire la pseudoformule mathématique suivante :
(L’exemple d’utilisation est présenté dans le paragraphe présentant tally())
rss %>% count(ghm, sort = TRUE)
# Produit directement le case-mix classé par effectif décroissant
rss %>% count(ghm, name = "n_ghm")
# la colonne de résultat s'appèlera "n_ghm" add_count() est la version « fenêtre » c’est à dire sans agrégation :
> rss %>% count(sexe)
# A tibble: 2 × 2
sexe n
<int> <int>
1 1 12671
2 2 15846
> rss %>% add_count(sexe)%>% select(nrss, sexe, n)
# A tibble: 28,517 × 3
nrss sexe n
<int> <int> <int>
1 167447 2 15846
2 167448 2 15846
3 167449 1 12671
4 167450 1 12671
5 167451 1 12671
6 167452 1 12671
7 167453 2 15846
8 167454 1 12671
9 167455 1 12671
10 167456 2 15846
# ℹ 28,507 more rows
# ℹ Use `print(n = ...)` to see more rows Compter/pondérer un regroupement : tally()
tally(), par défaut compte les lignes en respectant le group_by() mais ne peut pas s’en passer si vous voulez grouper (à la différence de count() qui prend les champs en paramètres). La fonction est là pour remplacer uniquement summarise(n=n()) dans la version sans paramètre ou summarise(n=sum(x)) avec. Ainsi :
rsa %>% group_by(ghm) %>% tally(ds)
# est l'équivalent de
rsa %>% group_by(ghm) %>% summarise(n = sum(ds))
# en l'absence de paramètre cela devient :
rsa %>% group_by(ghm) %>% summarise(n = sum(1))
# qui est équivalent à
rsa %>% group_by(ghm) %>% summarise(n = n())
# et donc à
rsa %>% count(ghm)Comme pour count(), il existe add_tally() qui fenêtre la fonction, il est possible de préciser le nom de la colonne résultat avec name= et, pour tally() seulement, trier avec sort=.
Conclusion
Nous arrivons à la fin de notre 2ème article sur la migration SQL vers R. Nous avons vu l’équivalent SQL des fonctions d’agrégation et de fenêtrage et comment faire potentiellement encore beaucoup plus car R nous permet de faire absolument tout ce que nous voulons.
La prochaine fois, nous nous pencherons sur les jointures. Là aussi la transition est assez directe tout en facilitant certaines constructions confuses en raison de la structure rigide de SQL.
Dans l’intervalle quelques exercices (cliquez dessus pour la réponse)
A quoi sert ce code ? Traduisez-le en R :
SELECT t.nda AS NDA,
t.nrss AS NRSS,
SUM(t.dsort – t.dent) AS DS,
COUNT(t.nda) AS nRUM
FROM rss AS t
GROUP BY t.nda, t.nrss
HAVING COUNT(t.nda) > 1
ORDER BY nRUM DESC;
# Ce code sert à isoler les séjours multi-rums
# et les lister par nombre de RUM décroissants
# en précisant pour chacun le nombre de RUM et
#la durée totale de séjour.
rss %>%
group_by(nda, nrss) %>%
summarise(
ds = sum(dsort - dent),
nRUM = n()
) %>%
filter(nRUM > 1) %>%
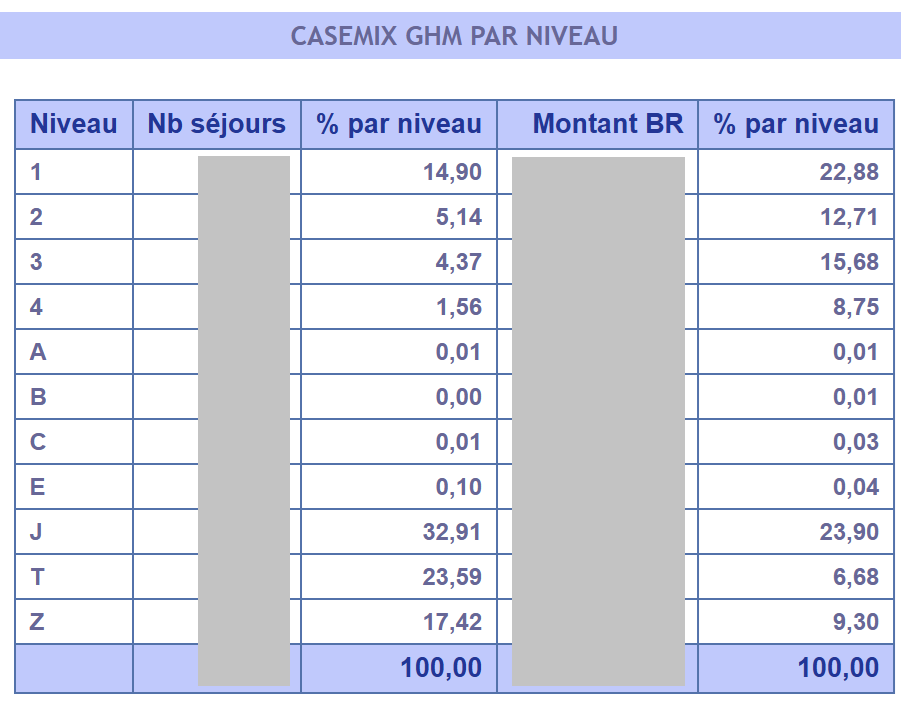
arrange(desc(nRUM))Ecrivez le code nécessaire pour produire le tableau « CASEMIX GHM PAR NIVEAU » tiré d’OVALIDE 1.V.5.SYNTS) (Vous avez un exemple ci dessous, les données ont été cachées mais sont bien sûr à calculer).
La dernière ligne n’est pas couverte par le présent article mais le sera dans un des suivants.
On supposera que la table source contient :
. nda : numéro de séjour,
. nrss : numéro de RSS,
. ghm : GHM résultant,
. sev : sévérité du GHM,
. montant_br : valorisation du séjour
table_casemix <- rsa %>%
group_by(sev) %>%
summarise(
`Nb séjours` = n(),
`Montant BR` = sum(montant_br, na.rm = TRUE),
.groups = "drop"
) %>%
mutate(
`% par niveau (séjours)` = round(100 * `Nb séjours` / sum(`Nb séjours`), 2),
`% par niveau (BR)` = round(100 * `Montant BR` / sum(`Montant BR`), 2)
) %>%
select(
Niveau = sev,
`Nb séjours`,
`% par niveau (séjours)`,
`Montant BR`,
`% par niveau (BR)`
)
# En SQL on écrirait :
# SELECT
# niveau,
# COUNT(*) AS "Nb séjours",
# ROUND(
# 100.0 * COUNT(*) / SUM(COUNT(*)) OVER (),
# 2
# ) AS "% par niveau (séjours)",
# SUM(montant_br) AS "Montant BR",
# ROUND(
# 100.0 * SUM(montant_br) / SUM(SUM(montant_br)) OVER (),
# 2
# ) AS "% par niveau (BR)"
# FROM sejours
# GROUP BY niveau; Pour rappel, il s’agit de ce tableau :