

(Note préliminaire : dans les extraits de code, si une ligne de code commence par « > », c’est qu’elle est tapée dans la fenêtre d’exécution (en bas à gauche, onglet « console »), le résultat -s’il existe- s’affiche alors immédiatement en dessous. Si le code est tapé dans la fenêtre de code (en haut à gauche), il ne s’exécutera que quand le fichier sera « sourcé »)
Pour ce premier programme, nous allons explorer le fonctionnement de R mais pas toucher au PMSI.
R est fourni avec des jeux de données tous prêts afin de pouvoir expérimenter
Ouvrons un nouveau fichier par la première icone du bandeau (ou par le menu « File -> New File »):
et sélectionnons « R Script ».
Un « script R » est le type le plus simple de fichier traitable par R. Il s’agit d’un enchainement de commandes exécutées l’une après l’autre jusqu’à la fin du fichier.
Une page blanche, éditable, apparait dans la fenêtre de code. Nous allons y taper nos premières lignes.
library(datasets)
1 + 2
calcul <- 2 + 3
calcul
donnees <- infert
donnees[,2]
donnees$age
Nous avons certes tapé ce code, mais il ne se passe rien car une fois tapé, il faut l’exécuter. Pour cela, le plus simple est de cliquer sur « Source with Echo » (« Run » ne fait qu’exécuter la ligne sur laquelle est le curseur) :

L’exécution se déroule… dans la fenêtre d’exécution (en bas à gauche).
Détaillons donc ce morceau de code :
library(datasets)
Permet de charger une librairie, c’est à dire un ensemble de fonctions et données fournies par R ou par un tiers dans le but d’étendre le langage. Dans le cas présent, « datasets » est la librairie contenant des jeux de données préformatés pour faire des essais.
1 + 2
Retourne simplement dans la fenêtre d’exécution le résultat de l’addition :
> 1 + 2
[1] 3A noter la façon d’écrire « [1] 3 », cela signifie que le code retourne 1 ligne dont la valeur est 3 (pas de guillemets donc une valeur numérique).
Mais pourquoi préciser « [1] » ?
Parce que R est destiné à traiter des ensemble de données, on peut donc aussi faire travailler des fonctions sur des tables de données, nous y reviendrons.
calcul <- 1 + 2
Il s’agit là de l’instanciation d’un variable nommée « calcul » avec le contenu de ce qui est à droite.
La fenêtre d’exécution ne montre pas de sortie par contre dans la fenêtre de données (en haut à droite), onglet « Environment », on voit apparaitre la variable « calcul » et son contenu (s’il est affichable, son type sinon) :

Il existe 3 principales façons d’instancier ainsi une variable :
- « <- » : met le contenu donné à droite dans la variable à gauche
- « -> » : met le contenu donné à gauche dans la variable à droite
- « = » : met le contenu donné à droite dans la variable à gauche
Il existe de petites différences entre chaque. La règle la plus importante est de privilégier « <- » à « = » dans le code et de réserver « = » pour les appels de fonctions avec des paramètres nommés (nous y reviendrons). Et « <- » est plus lisible que « -> » car ainsi on sait dès le début que c’est une instanciation
donnees <- infert
Cette ligne attribue l’ensemble de données « infert » (défini dans « datatsets », Infertility after Spontaneous and Induced Abortion) à la variable « donnees ». Là non plus, il n’y a pas de sortie à l’écran dans la fenêtre d’exécution mais on voit apparaitre « donnees » dans la fenêtre de données :

(Dans les faits, cette attribution n’est pas nécessaire et on pourrait utiliser directement « infert » qui est défini dans « datasets » mais qui nous est juste « caché » par sa définition dans une librairie).
On apprend que « donnees » contient 248 observations de 8 variables, c’est à dire que c’est un tableau de 8 colonnes et 248 lignes.
Il est possible en cliquant sur la flêche située devant de dérouler la structure de « donnees » :
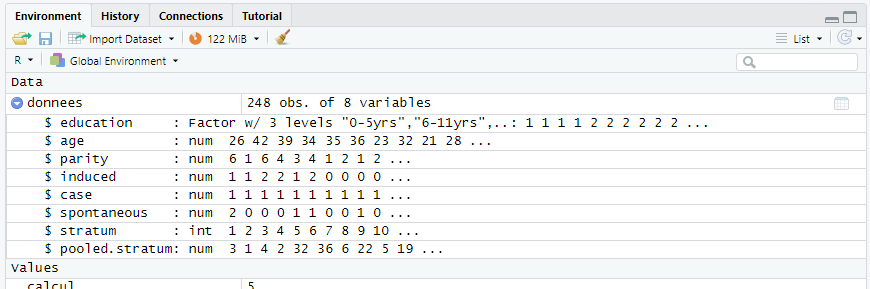
ce qui nous permet d’avoir un aperçu du contenu du jeu de données. Celui ci est constitué de
- education : champ de type « factor » (un champ numérique entier mais dont la présentation est une chaine de caractère)
- age, parity, induced, case, spontaneous, pooled.stratum : un champ numérique (à virgule potentiellement)
- stratum : un champ numérique entier
En cliquant sur la ligne d’entête « donnees », le contenu du jeu de données s’ouvre dans un nouvel onglet de la fenêtre de code, permettant de le parcourir de façon plus conviviale :
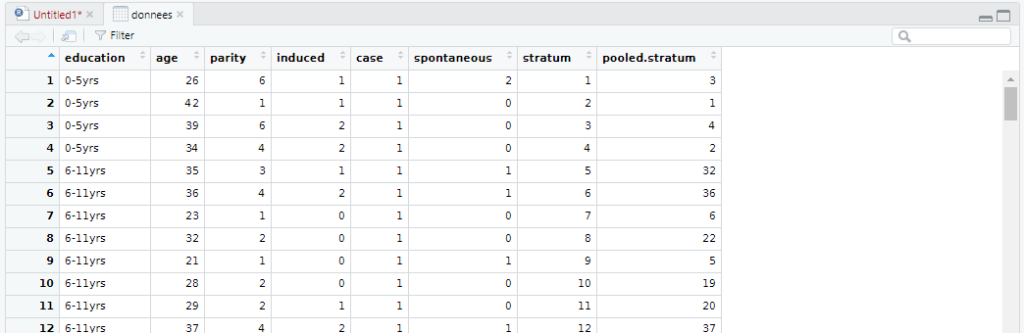
Enfin, nous avons la ligne
donnees[,2]
qui demande à R d’extraire la 2ème colonne du jeu de données pour affichage dans la fenêtre d’exécution :

(vous voyez ici que 248 valeurs ont été retournées)
il y a d’autres façons d’écrire cela, par exemple :
donnees$age
donnees[,"age"]
qui donnent le même résultat mais en nommant la colonne désirée, rendant le code plus clair et n’imposant pas de respecter strictement un ordre de colonnes.
Volontairement je n’ai pas cité donnees[2] -qui fonctionne aussi- car cette écriture est piégeuse, vous verrez plus loin lorsque nous essayerons de filtrer le jeu de données.
Pour aller plus loin
Les vecteurs
Une des particularités de R est qu’il travaille par défaut sur ce qu’il appelle des vecteurs (vectors en anglais). Toute variable est un vecteur, tout jeu de données est un ensemble de vecteurs.
Ainsi, le nombre 5 est un vecteur de type numérique contenant 1 seule valeur, 5. Cependant, on peut par exemple avoir une variable vec <- c(1,5) qui alors est un vecteur de type numérique contenant 2 valeur, 1 et 5. Pour créer un vecteur, il suffit d’utiliser la fonction de concaténation c().
Attention cependant, on ne peut concaténer que des valeurs de même type (ou transposables) :
> c(1,4)
[1] 1 4 # 2 valeurs numériques entières
> c(1,4.3)
[1] 1.0 4.3 # 2 valeurs numériques flottantes
> c(1,4.3,"5")
[1] "1" "4.3" "5" # 3 chaines de caractères
Il faut bien comprendre que même si contenant plusieurs valeurs, il s’agit d’une seule variable vec et que pour accéder à son/ses contenus, il faut aller les chercher :
> vec[1]
[1] "1"
> vec[2]
[1] "4.3"
> vec[3]
[1] "5"
> vec
[1] "1" "4.3" "5"
Sélectionner plusieurs colonnes
Maintenant que nous savons ce que sont les vecteurs et comprenons qu’ils sont partout dans R, sélectionner plusieurs colonnes devient simple. Il « suffit » de préciser un vecteur de colonnes :
> donnees[,c("age","parity")]
age parity
1 26 6
2 42 1
3 39 6
4 34 4
5 35 3
6 36 4
7 23 1
8 32 2
9 21 1
10 28 2
11 29 2
12 37 4
13 31 1
14 29 3
...
Et voilà, le jeu de données retourné ne contient que les colonnes demandées.
Restreindre un jeu de données
De même qu’il est possible de restreindre les colonnes, il est possible de ne vouloir traiter qu’un sous-ensemble d’un jeu de données, pour cela il faut pouvoir spécifier quelles lignes nous intéressent. C’est la raison d’être de la virgule dans donnees[,"age"]. Les crochets permettent de définir les lignes (les observations en langue R) et les colonnes à afficher. Ainsi :
> donnees[5,]
education age parity induced case spontaneous stratum pooled.stratum
5 6-11yrs 35 3 1 1 1 5 32
ne retourne que la 5ème observation.
Notez l’utilisation impérative de la virgule entre les crochets pour éviter de sélection la 5ème colonne et la raison pour laquelle je vous déconseillais plus haut d’utiliser la notation sans virgule.
Mais il est aussi possible de préciser en lieu et place un vecteur de 248 valeurs vraies (TRUE) ou fausses (FALSE) permettant de sélectionner ou non telle ou telle observation. Et ce vecteur peut être calculé.
Il est alors possible de filtrer le jeu de données par exemple en faisant :
> donnees[(donnees$age > 35),]
education age parity induced case spontaneous stratum pooled.stratum
2 0-5yrs 42 1 1 1 0 2 1
3 0-5yrs 39 6 2 1 0 3 4
6 6-11yrs 36 4 2 1 1 6 36
12 6-11yrs 37 4 2 1 1 12 37
20 6-11yrs 44 1 0 1 1 20 17
21 6-11yrs 40 1 0 1 1 21 14
24 6-11yrs 36 1 0 1 1 24 12
26 6-11yrs 40 2 0 1 2 26 27
27 6-11yrs 38 2 0 1 2 27 26
33 6-11yrs 42 1 1 1 0 33 16
qui sélectionne uniquement les observations correspondant au critère (notez la colonne 0 qui n’est pas continue, les observations ne correspondant pas ont été « sautées »).
Les différents types de tests
Nous n’allons pas voir tous les tests possibles mais juste les plus simples :
- L’égalité : elle s’écrit « == » (2 signes égal à la suite) afin de se différencier de « = » que nous avons vu plus haut.
- L’inégalité : « != » (point d’exclamation suivi d’un signe égal)
- Les comparaisons : comme habituellement « <« , « > » et « <= », « >= ». Attention, « =< » et « => » ne sont pas valides
Les éléments logiques :
- Le ET : « & »
- Le OU : « | »
- Le OU exclusif : il n’a pas de forme courte, on doit utiliser
xor(...) - Le NON : (qui inverse le résultat de ce qui suit) : « ! »
Exemples :
> TRUE & FALSE
[1] FALSE
> TRUE | FALSE
[1] TRUE
> xor(TRUE, FALSE)
[1] TRUE
> xor(TRUE, TRUE)
[1] FALSE
> ! TRUE
[1] FALSE
Exécuter une fonction sur un jeu de données
Il est possible d’appliquer un traitement (une fonction) sur un ensemble de données. Par exemple, pour calculer la moyenne d’âge du jeu de données, on fait simplement :
> mean(donnees$age)
[1] 31.50403
« mean » étant une fonction prédéfinie de R.
Fort de notre connaissance ci-dessus, nous pouvons répondre à la question « Quel est l’âge moyen des pares > 3 ? » :
> mean(donnees[donnees$parity > 3, "age"])
[1] 32.65625
En clair, nous demandons à R de sélectionner les observations dont la colonne parité (parity) est > 3, de ne garder que la colonne « age » puis d’en tirer la moyenne.
Quelques exercices
Sur le jeu de données que nous avons utilisé, essayez de :
- calculer la moyenne d’âge du 1er IVG (« induced » contient le nombre d’IVG préalable)
- la moyenne d’âge du niveau d’éducation « 6-11 yrs »
# moyenne d'âge du 1er IVG
> mean(donnees[donnees$induced==1,"age"])
[1] 30.80882
# moyenne d'âge du niveau d'éducation "6-11 yrs"
mean(donnees[donnees$education=="6-11yrs","age"])
résultat : 32.85Conclusion
C’est tout pour ce premier petit morceau de code, la prochaine fois nous allons essayer d’oublier un bon morceau de ce que je viens de vous présenter pour rentrer dans le R du 21è siècle grâce au Tidyverse et en particulier aux deux librairies « magrittr » et « dplyr » qui simplifient énormément la capacité d’évocation du langage.