

Aujourd’hui nous allons nous charger de valoriser un séjour selon son GHS.
Le principe
Un séjour est caractérisé par une durée de séjour DS et un numéro de GHS … GHS. Ce couple de données permet de calculer la valorisation de base de ce séjour selon un calcul basé sur des données nationales fixées au JO lors des arrêtés tarifaires annuels.
Il existe 3 zones dépendant de la DS dans de calcul de la valorisation:
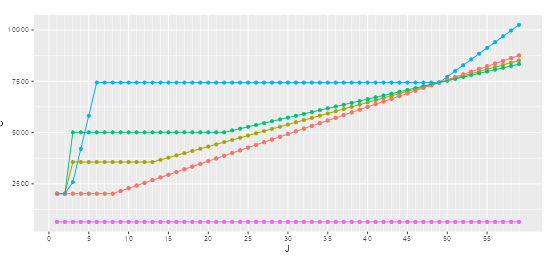
(Mauve :Très courte durée, Rouge : SEV1, Kaki : SEV2, Vert : SEV3, Bleu : SEV4)
Le Plateau : correspondant à une valorisation d’un séjour entre la Borne Basse (BB) et la Borne Haute (BH).
L’Extrême Bas : La partie à gauche du graphe, avant le plateau, où la DS est inférieure à la BB
L’Extrême Haut : La partie à droite du graphe, où la DS est supérieure à la BH.
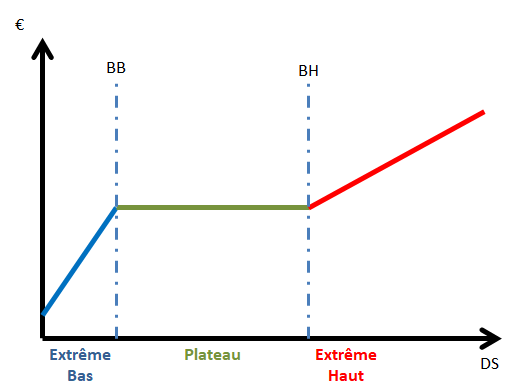
Les valeurs de BB et BH sont variable selon les GHS et jusqu’à il y a peu, les règles de calculs de l’Extrême Bas pouvaient varier aussi avec l’existence d’un « forfait » FORFAIT-EXB.
Dans la mesure où il pourrait être nécessaire de valoriser des séjours d’années précédentes, nous allons créer une fonction gérant aussi bien les EXB que le FORFAIT-EXB.
Les données des séjours
Il nous faut le GHS officiel, il est donc nécessaire de se baser sur le RSA car il est absent des fichiers « in ».
Le GHS est calculé par GENRSA lors du groupage et exporté dans le RSA. Dans le format 2022, à l’emplacement 96-99.
La DS est elle-aussi calculée par GENRSA et exportée dans le RSA en 72-74.
Techniquement GENRSA calcule aussi le nombre d’EXB (105-107) et d’EXH (100-103) générés par un séjour. Nous n’allons pas nous y intéresser car les règles de valorisation (les bornes BB, BH et le type d’EXB) peuvent varier d’année en année et nous pourrions vouloir étudier la variation de valorisation au cours des réformes ; ce qui ne serait pas possible si nous nous basions sur les EXB et EXH déjà calculés.
Les données de référence
Les données de GHS
Il nous faut une base officielle de calcul. A cette fin, l’ATIH fournit annuellement une archive regroupant les différents tarifs publics et privés : https://www.atih.sante.fr/tarifs-mco-et-had
Dans cette archive se trouve un fichier « ghs_***.csv » (***= »pub » ou « pri » selon votre statut) contenant une partie de ce dont nous avons besoin (exemple, toujours avec 09M08) :

A un GHS-NRO correspond les paramètres de calculs (colonnes de SEU-BAS à EXH-PRI).
Attention, dans la copie d’écran ci-dessus, vous noterez que 09M081 et 09M08T sont dédoublés mais cela ne nous pose pas de problème car GHS-NRO est unique et seul nous intéresse le lien GHS-NRO –> GHM-NRO
si vous voulez utiliser refpmsi, pas de soucis mais n’oubliez pas de lire cette note. De plus, refpmsi dédouble les ghs UHCD sur toutes les sévérités, il faut donc les supprimer (comme illustré dans l‘article précédent). Quoi qu’il en soit, dans la suite de l’article, je ne l’utiliserai pas afin de montrer comment on charge un fichier au format CSV.
Les règles de calcul
L’algorithme de valorisation peut s’écrire :
si DS >=BB et DS <= BH alors
VALORISATION = FORFAIT
sinon, si DS < BB alors
si FORFAIT_EXB n'existe pas ou FORFAIT_EXB = 0 alors
VALORISATION = FORFAIT - (BB - DS) * EXBPRI
sinon
VALORISATION = FORFAIT - FORFAIT_EXB
sinon, si DS > BH alors
VALORISATION = FORFAIT + (DS - BH) * EXHPRI
(Comme déjà dit, FORFAIT_EXB a existé mais n’est plus utilisé, si la colonne existe elle est désormais toujours à 0)
En pratique
Le fichier des GHS
Le fichier disponible sur la page de l’ATIH est un fichier zip contenant le fichier qui nous intéresse au format « CSV séparé par des points-virgules » (avec un encodage « iso-8859-1 »).
Il va nous falloir l’importer dans notre environnement de travail.
Charger le fichier CSV
Il existe plusieurs « saveurs » de fichier CSV, selon la nature du séparateur, la présence de guillemets autour des chaines, le format des nombres, du retour à la ligne et l’encodage du texte.
R possède une série de fonctions grâce à la librairie readr pour attaquer ce type de fichiers : read_csv(), read_csv2(), read_tsv() et read_delim(). Bien que leur fonctionnement soit assez similaire, elles ont chacun leurs spécificités sauf read_delim() qui est la version « générique ».
| Fonction | Séparateur de champs | point décimal | point de groupement numérique | Délimitateur de chaine |
| read_csv() | , | . | , | » « |
| read_csv2() | ; | , | . | » « |
| read_tsv() | <tabulation> | . | , | » « |
| read_delim() | (configurable) | (configurable) | (configurable) | (configurable) |
Les prototypes de fonctions sont assez similaires avec juste les champs préréglés différemment. Je vais vous juste vous lister les paramètres et leur explication :
- <nom de fichier> : assez logiquement une vecteur de chaines comportant un ou des noms de fichiers à charger
- delim : le délimitateur interchamps (les version csv/csv2/tsv préremplissent ce champ à ,/;/<tab> respectivement)
- quote : le caractère marquant le début ou la fin d’une chaine de caractère
- escape_backslash : TRUE ou FALSE selon si on veut que l’antislash « \ » soit le caractère d’échappement
- escape_double : TRUE ou FALSE selon si on veut autorisé l’échappement des guillemets par leur dédoublement (c’est un truc très MS Windows…) : Si j’écris 1; »bon » »jou » »r », il sera lu les champs 1 puis bon »jou »r. sans ce paramètre, il faut saisir 1; »bon\ »jou\ »r »
- col_names : TRUE (défaut) si on veut que les noms de colonnes servent de nom de champ, FALSE si on veut qu’ils soient nommés arbitrairement, et un vecteur de chaines pour leur attribuer des noms désignés
- col_types : NULL si la fonction doit se débrouiller pour deviner, une chaine de caractères où chaque occurrence décrit le format contenu, ou le résultat d’un appel à
cols(). Sont disponibles pour la chaine de caractères :- c = character
- i = integer
- n = number
- d = double
- l = logical
- f = factor
- D = date
- T = date-time
- t = time
- ? = à deviner
- _ or – = ne pas garder la colonne
- col_select : NULL = tout, sinon une sélection de colonnes à conserver soit sous forme d’un vecteur de chaines ou de nombres, selon le même fonctionnement que la fonction
select()de dplyr. - id : une chaine de caractères définissant le champ qui contiendra le nom du fichier à l’origine de la ligne
- locale : les paramètres de localisation (l’encodage, le format de dates, le point décimal, etc).
- na : les valeurs qui seront transformées en NA lors de la lecture, par défaut la chaine vide et la chaine « NA »
- quoted_na : TRUE si on veut accepter « NA » (avec guillemets) comme la valeur NA
- comment : une chaine de caractères définissant la fin des données utiles d’une ligne
- trim_ws : TRUE ou FALSE selon s’il faut enlever les espaces en début et fin de chaines à l’importation
- skip : (défaut 0) le nombre de lignes à sauter dans le fichier avant de commencer à lire
- n_max : (défaut Infini) le nombre de lignes à lire
- guess_max : (défaut min(1000, n_max) ) le nombre de lignes sur lequel la fonction va se baser pour deviner les types.
- skip_empty_rows : comme son nom l’indique, n’importe pas les lignes vides si réglé à TRUE
- name_repair, num_threads, progress, show_col_types, lazy sont du réglage de détail souvent laissés en état
Dans notre cas, à la lecture du fichier brut, nous voyons qu’il faut régler au minimum :
read_delim(
"ghs_pub.csv",
delim = ";",
escape_double = FALSE,
locale = locale(
decimal_mark = ",",
encoding = "ISO-8859-1"
),
trim_ws = TRUE
)
pour être bien, en autodétection des types :
Rows: 3698 Columns: 12
-- Column specification -----------------------------------------------------------------------------------------------------------------------
Delimiter: ";"
chr (5): CMD-COD, DCS-MCO, GHM-NRO, GHS-LIB, DATE-EFFET
dbl (7): GHS-NRO, SEU-BAS, SEU-HAU, GHS-PRI, EXB-FORFAIT, EXB-JOURNALIER, EXH-PRI
i Use `spec()` to retrieve the full column specification for this data.
i Specify the column types or set `show_col_types = FALSE` to quiet this message.
# A tibble: 3,698 x 12
`GHS-NRO` `CMD-COD` `DCS-MCO` `GHM-NRO` `GHS-LIB` SEU-B~1 SEU-H~2 GHS-P~3 EXB-F~4 EXB-J~5 EXH-P~6 DATE-~7
<dbl> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <chr>
1 22 01 C 01C031 "Craniotomies pour traumatisme, \xe2ge sup\~ 0 11 3775. 0 0 112. 01/03/~
2 23 01 C 01C032 "Craniotomies pour traumatisme, \xe2ge sup\~ 0 19 6703. 0 0 92.3 01/03/~
3 24 01 C 01C033 "Craniotomies pour traumatisme, \xe2ge sup\~ 0 64 12096. 0 0 71.6 01/03/~
4 25 01 C 01C034 "Craniotomies pour traumatisme, \xe2ge sup\~ 12 124 16391. 0 409. 304. 01/03/~
5 26 01 C 01C041 "Craniotomies en dehors de tout traumatisme~ 0 12 5920. 0 0 137. 01/03/~
6 27 01 C 01C042 "Craniotomies en dehors de tout traumatisme~ 0 20 9871. 0 0 103. 01/03/~
7 28 01 C 01C043 "Craniotomies en dehors de tout traumatisme~ 0 43 14253. 0 0 71.2 01/03/~
8 29 01 C 01C044 "Craniotomies en dehors de tout traumatisme~ 12 105 18664. 0 420. 371. 01/03/~
9 30 01 C 01C051 "Interventions sur le rachis et la moelle p~ 0 10 5061. 0 0 152. 01/03/~
10 31 01 C 01C052 "Interventions sur le rachis et la moelle p~ 0 17 7903. 0 0 125. 01/03/~
# ... with 3,688 more rows, and abbreviated variable names 1: `SEU-BAS`, 2: `SEU-HAU`, 3: `GHS-PRI`, 4: `EXB-FORFAIT`, 5: `EXB-JOURNALIER`,
# 6: `EXH-PRI`, 7: `DATE-EFFET`
# i Use `print(n = ...)` to see more rows
Nettoyage de propreté
Si on regarde les entêtes de colonne, on note la présence de backquotes (des apostrophes inversés : ` ) autour de la totalité des titres. La raison est la présence du signe « – » dans le noms de colonnes afin de différencier <GHS-NRO>, la colonne, et l’éventuel calcul <GHS> – <NRO>. Cela peut être source d’erreur d’interprétation et de bugs. Nous allons donc nettoyer ce jeu en remplaçant les titres. Ca n’est bien sûr pas obligatoire, et les noms donnés sont totalement arbitraires, chacun choisit ce qu’il veut.
Il est possible de le faire directement à la lecture via l’option col_names=en lui attribuant un vecteur de chaines de caractères de même longueur que les données extraites, où alors il est possible de les renommer a posteriori grâce à une ou des fonctions de dplyr telle que rename()(original, non ?).
(...) %>% rename(GHS = `GHS-NRO`,
CMD = `CMD-COD`,
DCS = `DCS-MCO`,
GHM = `GHM-NRO`,
LIB = `GHS-LIB`,
BB = `SEU-BAS`,
BH = `SEU-HAU`,
GHSPRIX = `GHS-PRI`,
FORFAIT_EXB = `EXB-FORFAIT`,
EXBPRIX = `EXB-JOURNALIER`,
EXHPRIX = `EXH-PRI`,
DEFFET = `DATE-EFFET`
)
En import automatique `DATE-EFFET` (devenu DEFFET) est assimilé à un champ texte. Là aussi, on pourrait le régler dès le chargement en spécifiant les types de colonnes dans col_types = ET en précisant le format attendu pour une date dans le locale()via l’option date_format = "%d/%m/%Y" (voyez l’aide de la fonction strptime() pour le sens de cette incantation).
Dans notre cas, pour pratiquer, on va le faire après en rajoutant ce traitement dans le pipe via :
(...) %>% mutate(DEFFET = as.Date(DEFFET, format = "%d/%m/%Y"))
(Dans les faits, on n’utilisera pas ce champ mais c’est pour l’exhaustivité)
Le RSA
Nous avons déjà vu dans l’article Etude de la RAAC grâce au RSA et R comment le charger. Reportez-vous y si besoin. Je vous le remets tel quel mais dans notre article nous n’auront besoin que de GHS et DS.
RSA <- read_fwf( file = fichierRSA,
col_positions = fwf_cols(GHMIN = c(31, 36),
RGHMIN = c(31, 35),
SEVIN = c(36, 36),
GHMOUT = c(42, 47),
RGHMOUT= c(42, 46),
SEVOUT = c(47,47),
GHS = c(96, 99),
DS = c(71, 74),
RAAC = c(199, 199)
),
coltypes = "cccccccic"
)
Le calcul en lui-même
Version brutale (non vectorisée)
En première lecture, un utilisateur imaginerait probablement un plaquage du pseudocode donné plus haut :
valorise = function(ghs, ds, bb, bh, ghsprix, forfait_exb = 0, exb, exh){
if (ds >= bb & ds <= bh) {
return(ghsprix)
} else if (ds < bb) {
if (forfait_exb > 0) {
return(ghsprix - forfait_exb)
} else {
return(ghsprix - (bb - ds) * exb)
}
} else if(ds > bh) {
return(ghsprix + (ds - bb) * exh)
} else { # Si tout se passe bien, on ne devrait pas arriver là.
stop("Problème de valorisation GHS:", ghs)
}
}
On pense donc qu’une telle fonction pourrait être utilisée pour valorisé un RSA ainsi :
> RSA %>% left_join(GHSs,by=c("GHS")) %>% mutate(valo=valorise(GHS,DS,BB,BH,GHSPRIX, 0,EXBPRIX,EXHPRIX))
# A tibble: 4 x 14
GHS DS CMD DCS GHM LIB BB BH GHSPRIX FORFA~1 EXBPRIX EXHPRIX DEFFET valo
<dbl> <dbl> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <date> <dbl>
1 22 10 01 C 01C031 Craniotomies pour traumatisme, âge supérieur à ~ 0 11 3775. 0 0 112. 2022-03-01 3775.
2 33 4 01 C 01C054 Interventions sur le rachis et la moelle pour d~ 14 84 16283. 0 268. 384. 2022-03-01 16283.
3 2345 2 07 C 07C123 Autres interventions sur les voies biliaires sa~ 0 40 10176. 0 0 209. 2022-03-01 10176.
4 2345 67 07 C 07C123 Autres interventions sur les voies biliaires sa~ 0 40 10176. 0 0 209. 2022-03-01 10176.
# ... with abbreviated variable name 1: FORFAIT_EXB
Warning message:
Problem while computing `valo = valorise(GHS, DS, BB, BH, GHSPRIX, 0, EXBPRIX, EXHPRIX)`.
i the condition has length > 1 and only the first element will be used
… et… ça ne fonctionne pas (notez que toutes les valorisations sont réalisées sur la base du forfait malgré la présence de BB et BH et il y a un warning inquiétant en bas de l’exécution)
En fait, nous avons déjà vu le principe de la vectorisation dans l’article Le “problème” de la vectorisation. Il se trouve qu’on utilise la fonction if()qui, nous l’avions vu alors, n’est pas vectorisée. En conséquence, if() a été appliqué sur la première ligne du tableau et son résultat appliqué sur toutes les lignes… Retour à la planche à dessin !… ou pas.
La « solution de facilité »
La première solution, de facilité, serait de simplement vectoriser comme décrit dans l’article Le “problème” de la vectorisation grâce à la fonction Vectorize():
valoriseV = Vectorize(valorise)
et nous avons alors bien :
> RSA %>% left_join(GHSs,by=c("GHS")) %>% mutate(valo=valoriseV(GHS,DS,BB,BH,GHSPRIX, 0,EXBPRIX,EXHPRIX))
# A tibble: 4 x 14
GHS DS CMD DCS GHM LIB BB BH GHSPRIX FORFA~1 EXBPRIX EXHPRIX DEFFET valo
<dbl> <dbl> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <date> <dbl>
1 22 10 01 C 01C031 Craniotomies pour traumatisme, âge supérieur à ~ 0 11 3775. 0 0 112. 2022-03-01 3775.
2 33 4 01 C 01C054 Interventions sur le rachis et la moelle pour d~ 14 84 16283. 0 268. 384. 2022-03-01 13602.
3 2345 2 07 C 07C123 Autres interventions sur les voies biliaires sa~ 0 40 10176. 0 0 209. 2022-03-01 10176.
4 2345 67 07 C 07C123 Autres interventions sur les voies biliaires sa~ 0 40 10176. 0 0 209. 2022-03-01 15819.
# ... with abbreviated variable name 1: FORFAIT_EXB
mais c’est utiliser la magie de Vectorize() sans comprendre.
La solution vectorisée « artisanale »
Pour écrire une fonction vectorisée à la source, il suffit de n’y utiliser que des fonctions elles-mêmes vectorisées. La nous allons utiliser ifelse().
valorise()devient donc :
#Version détaillée
valorise2 = function(ghs, ds, bb, bh, ghsprix, forfait_exb = 0, exb, exh){
nexb = bb - ds
nexh = ds - bh
vexb = ifelse(nexb>0, ifelse(forfait_exb > 0,
forfait_exb,
nexb * exb
), 0)
vexh = ifelse(nexh > 0, nexh * exh, 0)
ghsprix - vexb + vexh
}
#Version minimale
valorise3 = function(ghs, ds, bb, bh, ghsprix, forfait_exb = 0, exb, exh){
ghsprix + ifelse(ds < bb & forfait_exb > 0,
-forfait_exb,
-ifelse(ds < bb, bb - ds, 0) * exb + ifelse(ds > bh, ds - bh, 0) * exh
)
}
Et magie-magie :
> RSA %>% left_join(GHSs, by = c("GHS")) %>%
mutate(valo2 = valorise2(GHS, DS, BB, BH, GHSPRIX, FORFAIT_EXB, EXBPRIX, EXHPRIX),
valo3 = valorise3(GHS, DS, BB, BH, GHSPRIX, FORFAIT_EXB, EXBPRIX, EXHPRIX),
valoV = valoriseV(GHS, DS, BB, BH, GHSPRIX, FORFAIT_EXB, EXBPRIX, EXHPRIX))
# A tibble: 4 x 16
GHS DS CMD DCS GHM LIB BB BH GHSPRIX FORFA~1 EXBPRIX EXHPRIX DEFFET valo2 valo3 valoV
<dbl> <dbl> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <date> <dbl> <dbl> <dbl>
1 22 10 01 C 01C031 Craniotomies pour traumatisme, âg~ 0 11 3775. 0 0 112. 2022-03-01 3775. 3775. 3775.
2 33 4 01 C 01C054 Interventions sur le rachis et la~ 14 84 16283. 0 268. 384. 2022-03-01 13602. 13602. 13602.
3 2345 2 07 C 07C123 Autres interventions sur les voie~ 0 40 10176. 0 0 209. 2022-03-01 10176. 10176. 10176.
4 2345 67 07 C 07C123 Autres interventions sur les voie~ 0 40 10176. 0 0 209. 2022-03-01 15819. 15819. 15819.
# ... with abbreviated variable name 1: FORFAIT_EXB
Mais est-ce la bonne méthode ?
Nous avons maintenant une fonction de valorisation qui fonctionne, c’est bien. Mais il persiste, un inconvénient : il faut à chaque fois faire une jointure explicite avec la table des GHS.
Ne serait-il pas possible de s’en passer ? Par exemple en passant la table des GHS en paramètre de la fonction plutôt que de devoir intégrer le *_join().
On cherche donc à écrire une fonction avec ce type de prototype et d’utilisation :
RSA %>% mutate(valo = valorise4(GHS,DS,GHSs))
Avec Vectorize()
Et oui, Vectorize() permet aussi de faire cela directement grâce à ses options. Il suffit de préciser en paramètre vectorize.args=
valorise4 = Vectorise(valorise,vectorize.args=c("ghs","ds"))
Ainsi, seuls les paramètres de la fonction présent dans le vecteur vectorize.args= seront vectorisés, le reste sera passé en l’état..
Comme un vrai Riste
En fait, Vectorize fonctionne mais il y a une certaine satisfaction à comprendre et implémenter nativement ce que l’on cherche à faire.
valorise5 = function(ghs, ds, tGHS) {
mapply(function(a, b){
ghsinfos <- tGHS %>% filter(GHS == a)
with(ghsinfos, {
GHSPRIX + ifelse(b < BB & FORFAIT_EXB > 0,
-FORFAIT_EXB,
-ifelse(b < BB, BB - b, 0) * EXBPRIX + ifelse(b > BH, b - BH, 0) * EXHPRIX)
})
}, ghs, ds)
}
Cette fonction nous permet en plus d’introduire incidemment deux nouvelles fonctions : mapply() et with().
with()
with() permet d’importer dans l’environnement (= dans les variables accessibles) les données contenues dans l’objet passé en premier paramètre et exécute dans cet environnement augmenté le code en second paramètre :
> b <- "YOUPI"
> x <- list(a = "aaa", b = "bbb")
> a
Error: object 'a' not found
> with(temp,{print(c(a,b))})
[1] "aaa" "bbb"
> b
[1] "YOUPI"
> a
Error: object 'a' not found
Pour ceux qui ont déjà programmé en VBA (Access ou Excel), cela ressemble un peu à la structure pour accéder plus simplement au contenu d’un objet
Dim moi as New Personne
With moi
Debug.Print .NomDeFamille
Debug.Print .NomDeNaissance
End With
mapply()
mapply() est une des nombreuses fonctions de la série des ...apply(). C’est un élément central du traitement de vecteurs de façon itérative sans passer par des boucles, et il faudrait probablement un voire plusieurs articles pour les explorer.
Pour faire simple il s’agit de « multiple apply() » qui consiste à appliquer une fonction à plusieurs vecteurs et construire une liste contenant les valeurs de sortie. Le prototype (minimal) utilisé en est :
mapply(fonction_attendant_n_vecteurs, vecteur1, ..., vecteur n)
La fonction passée en premier paramètre peut être un nom de fonction (sans les (), ce qui l’exécuterait ) ou bien peut être (et est souvent) une fonction anonyme créée en place comme ici. Il convient alors de prévoir autant de paramètres à la fonction que de vecteurs passés à mapply().
Une autre voie
Pour le moment, nous avons pris le parti d’utiliser une fonction à intégrer à un mutate() permettant de préciser le nom du champ destination et les champs sources.
Cependant, il y a une possible autre voie à envisager pour une fonction du type (« df » pour data frame, le type socle des tableaux de données ; par opposition à ne rien mettre pour une fonction prenant des valeurs directes) :
RSA %>% valorise.ghs_df(GHSs)
L’avantage est que c’est encore plus concis et plus encore agréable à intégrer à une série de pipes.
Nous allons nommer valorise.ghs()une des versions de la fonction d’évaluation à partir du GHS et de la DS, pour le moment peut importe laquelle.
valorise.ghs <- valorise5
# Et oui, une fonction est un type de variable, on peut donc la réaffecter comme tel. Bien pratique pour tester différentes implémentations.
Il nous faut maintenant réfléchir aux options nécessaires pour rester souple. Voici les propositions d’un prototype et d’une implémentation se basant sur la fonction que nous avons écrite ci-dessus valorise.ghs() (il serait aussi possible de passer par la méthode « jointure puis calcul » mais il faudrait alors penser à faire un brin de ménage avant et après pour ne garder que les champs d’entrée et celui de sortie, bon exercice soit dit en passant).
valorise.ghs_df <- function (x, ghss, ghs_col = "GHS", ds_col = "DS", out_col="valo"){
if (out_col %in% names(x)) stop("la colonne de sortie `", out_col, "`` existe déjà.")
if (!(ghs_col %in% names(x))) stop("la colonne du GHS `", ghs_col, "` est absente du jeu source.")
if (!(ds_col %in% names(x))) stop("la colonne de durée de séjours `", ds_col, "` est absente du jeu source.")
suppressWarnings(if (is.na(ghss) | !("data.frame" %in% class(ghss))) stop("ghss doit être une data.frame au format attendu."))
x %>% mutate("{out_col}" := valorise.ghs(.data[[ghs_col]],.data[[ds_col]],ghss))
}
La partie magique se passe dans le mutate(), qu’il faut lire comme « crée un champ dont le nom est dans out_col en appliquant la fonction valorise.ghs() aux colonnes dont les noms sont dans ghs_col et ds_col du jeu de données en entrée et avec comme dernier paramètre le contenu de la variable ghss« .
Conclusion
Et voilà nous avons une jolie fonction de valorisation du GHS et deux façons de l’appeler.
Pour le sport, je vous propose de réfléchir à comment vous écririez les fonctions de valorisation des suppléments (« un indice pour vous qui êtes chez vous », il existe un fichier « sup_***.csv » dans l’archive de l’ATIH).
Toujours est-il, cet article était plutôt dense et nous allons une prochaine fois l’intégrer à nos requêtes sur le RAAC. Mais avant, nous regarderons quelle version de la fonction est la plus pertinente. A bientôt !