

Cet article va aborder des principes généraux pour vous aider à réaliser des graphiques pertinents avec ggplot2 au sein de vos explorations en R.
Comme souvent, l’hégémonie et la philosophie d’Excel sont des freins au bon usage des graphiques. Leur simplicité d’accès et le fait qu’on puisse changer totalement leur présentation en quelques clics, quoique donnant l’impression de la facilité pour l’utilisateur, lui évite de devoir réfléchir à ce qu’il fait réellement. Ainsi on se retrouve parfois avec des graphiques non pertinents, ne réussissant pas à transmettre de message clair vers les membres de l’audience.
En R/ggplot2, il est possible de changer une géométrie facilement en remplaçant juste geom_XXXX() par geom_YYYY() en adaptant parfois l’esthétique liée. Cependant, il y a une autre façon : choisir la bonne géométrie du premier coup (Merci Captain Obvious !). Pour cela, il faut connaitre et maitriser ses données.
Mais on fait comment alors ?
Construire un graphique, c’est chercher à transmettre un message. Et pour que le message soit percutant, il faut bien cerner le sujet. Dans notre cas, il s’agit de bien choisir la ou les variables à présenter ainsi que définir les sous-groupes pertinents.
Connaître les domaines auxquels chaque type de graphique est adapté.
Les graphiques peuvent être grossièrement divisés en familles selon le type de données principales qui leurs sont adaptées et/ou le but de leur présentation.
Une point de départ habituel de la réflexion est ci-dessous :
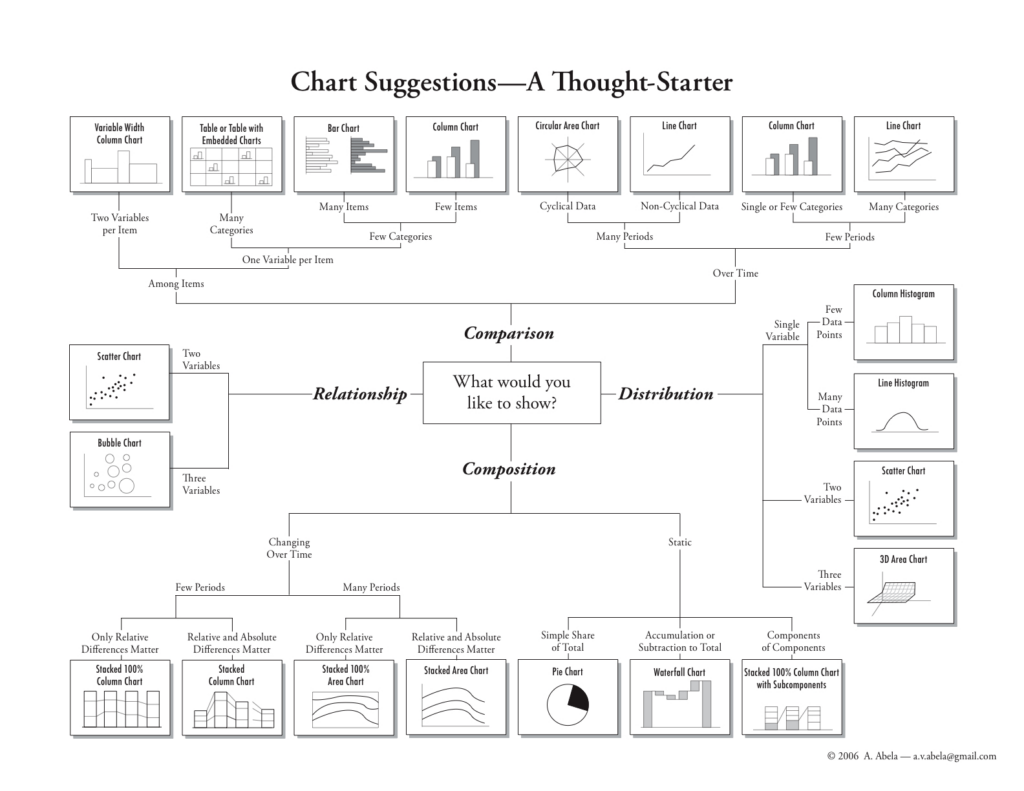
C’est là l’opinion de l’auteur de cette slide et chacun a le droit d’en avoir d’autres (par exemple, je n’utilise quasiment jamais de « camemberts » (pie chart, graphiques en secteurs)).
Mais ce qu’il faut en en tirer c’est qu’un graphique percutant se réfléchit.
- Selon ce que vous voulez mettre en avant,
- Selon votre audience,
- Selon le type (ci-dessous) de vos données,
- Selon le nombre de variables principales et accessoires,
… certains types de graphiques sont plus pertinents que d’autres.
Connaitre ses données
Dans la série d’articles sur les types (commençant avec Le typage des variables : les types de base), nous avons vu l’importance d’utiliser le bon type pour représenter nos données. Il en est de même pour réaliser des graphiques pertinents. Les critères sont plus fonctionnels, nous allons les voir plus en détail et illustrer leur pertinence.
Indépendamment du type « informatique », un vecteur de données peut se qualifier de :
qualitatif vs dénombrable
Une donnée dénombrable représente une valeur pour elle-même sur laquelle il est possible de réaliser des opérations mathématiques.
Une donnée qualitative signifie que bien que l’ensemble des valeurs du vecteur soit du même type, la signification qu’il apporte ne dérive pas de ses propriétés mathématiques.
Dans un RSS, le numéro FINESS bien qu’une valeur numérique est de type qualitatif car FINESS+1 n’a pas sens : il n’y a pas de lien logique ou mathématique entre les FINESS de 2 établissements. Alors que la le nombre de séances (NSEA chez moi) est une valeur numérique dénombrable : un RSS avec NSEA = 10 séances a un sens par rapport à un RSS ou NSEA = 9, le premier a fait une séance de plus.
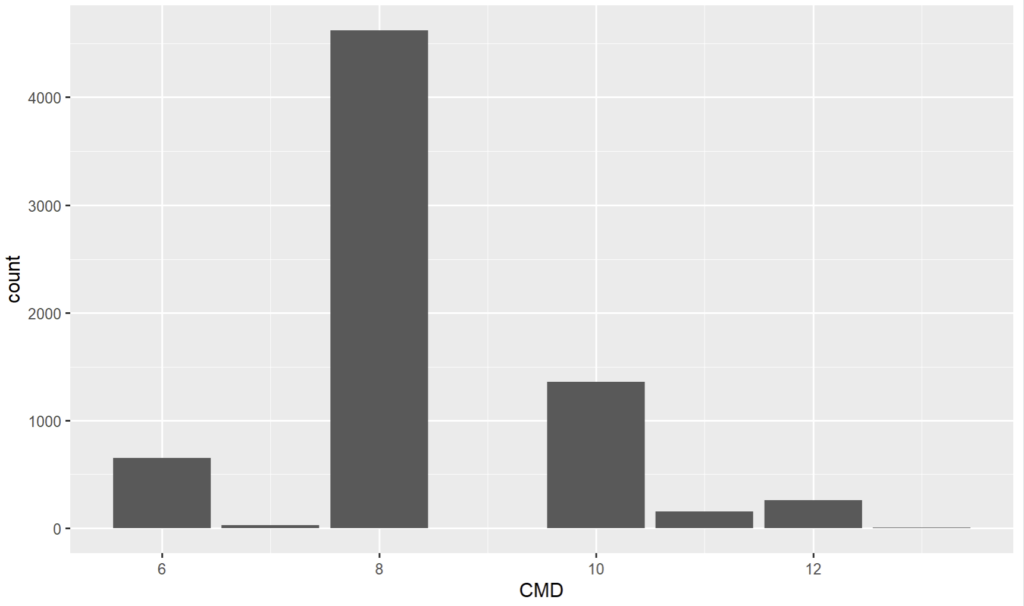
Exemple : Une étude de la CMD d’une sélection de séjours (les RAAC d’une fois précédente)
D’abord avec une CMD manipulée comme dénombrable:
Les mêmes données sous forme de données qualitatives :
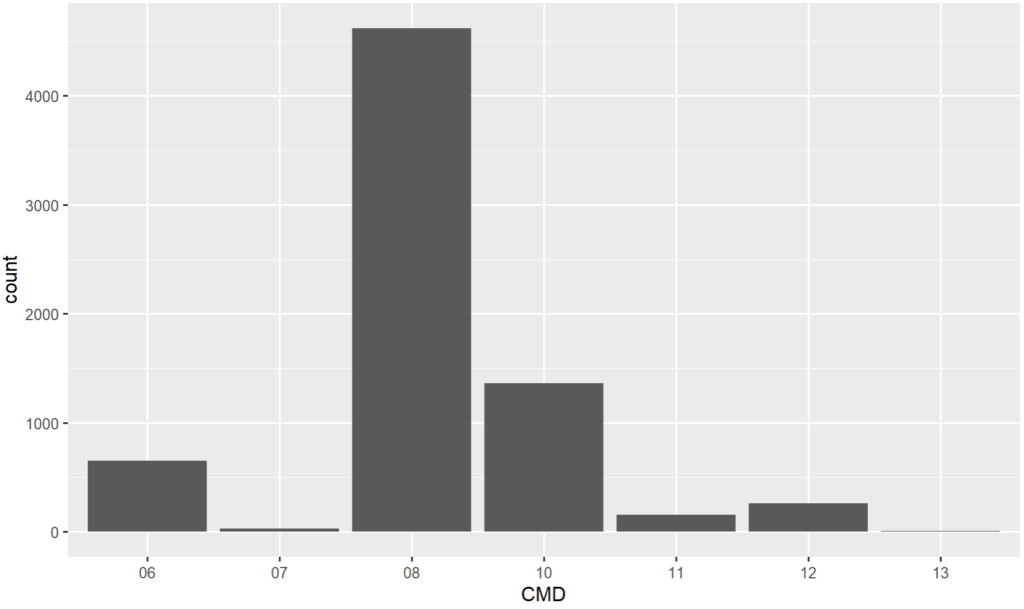
On voit les différences suivantes :
- Par défaut, ggplot a adapté l’échelle numérique du 1er graphique en n’indiquant qu’un nombre sur deux alors que rien ne garantirait que la CMD 07 est entre 06 et 08.
- La CMD 09 qui n’est pas dans le jeu de données est représentée dans la version quantitative (entre 8 et 10 assez logiquement), ce qui fausse le rendu faisant croire que des dossiers existent dans cette CMD dans le jeu.
Si nous avions eu une séance (CMD 28) perdue dans le jeu de données, dans le 1er cas (quantitatif), des colonnes vides de 14 à 27 auraient été créées. Dans le second cas, la CMD 28 serait collée à la CMD 13 ce qui est le comportement le plus visuellement adapté.
discret (au sens mathématique) vs continu, éventuellement cyclique vs acyclique
Une variable discrète est une donnée qui évolue « par bonds » sans pouvoir atteindre l’ensemble de son domaine de définition, tandis qu’une donnée continue peut prendre toutes les valeurs potentielles.
Une variable qualitative est obligatoirement discrète, tandis qu’une variable dénombrable peut être discrète ou continue.
Dans le cas d’un calcul de valorisation, le numéro de GHS est une variable qualitative-discrète (le GHS x n’a pas obligatoirement de signification par rapport au GHS x+1. Tandis que la durée de séjour (DS) est dénombrable-continue sur l’ensemble des nombres entiers positifs (ℕ+, vous vous souvenez de vos cours de maths de lycée ?) mais serait dénombrable-discrète sur l’ensemble des nombres réels positifs (ℝ+).
Une donnée est cyclique, si elle évolue de façon répétitive dans un ensemble borné. toutes les valeurs possibles représentent une période et il y a une pertinence à ce que la fin d’une période se raccorde avec le début de la période suivante. Tout ce qui est date infra-annuelle par exemple est potentiellement cyclique selon la taille de l’échantillon (supra-annuelle aussi mais assez peu à l’échelle du PMSI) :
- jour de l’année (période de 365 ou 366) *
- mois de l’année (période de 12)
- jour du mois (période de 28, 29, 30 ou 31 jours) *
- semaine de l’année (période de 52)
- jour de la semaine (période de 7)
- heure du jour (période de 24)
* : La gestion des dates-heures est un sujet très particulier surtout en ce qui concerne les « anomalies remarquables » que sont les années bissextiles, les secondes intercalaires ou la gestion des changements d’heures. Ce sera l’objet d’un article spécifique un de ces jours.
Exemple :
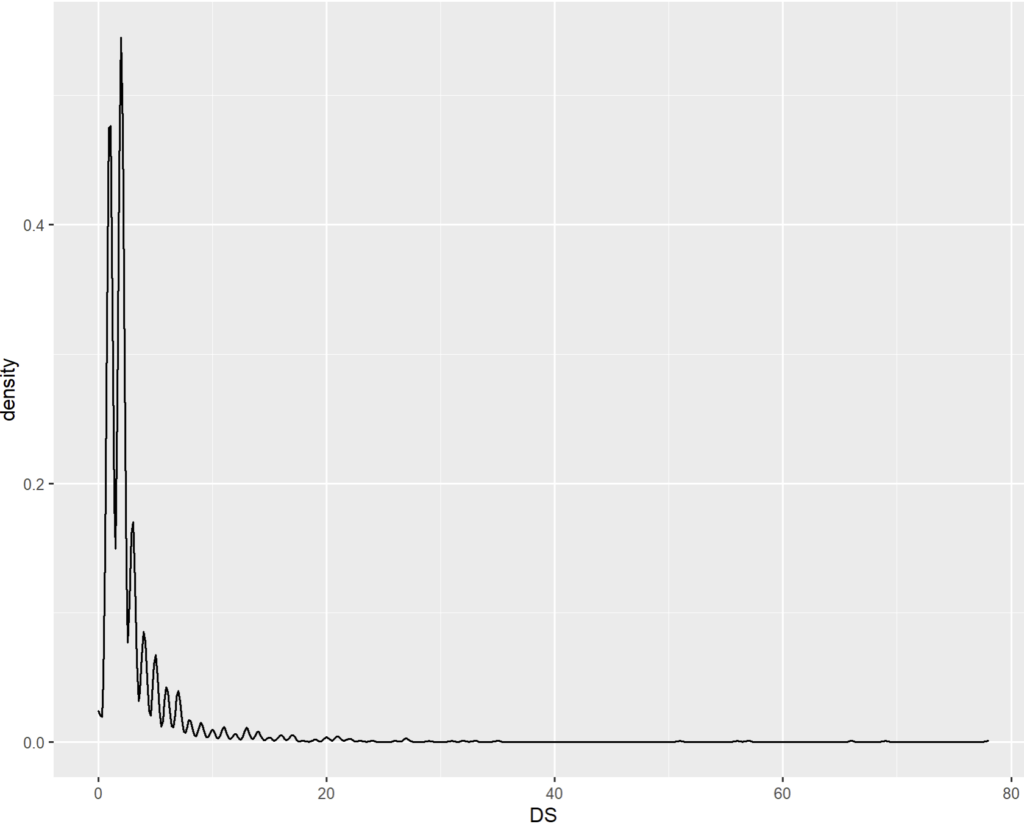
Un étude la durée de séjour avec un type de graphique dont la résolution est inférieur à 1 jour.
L’aspect dentelé est un artéfact indésirable lié à cette granularité des données.
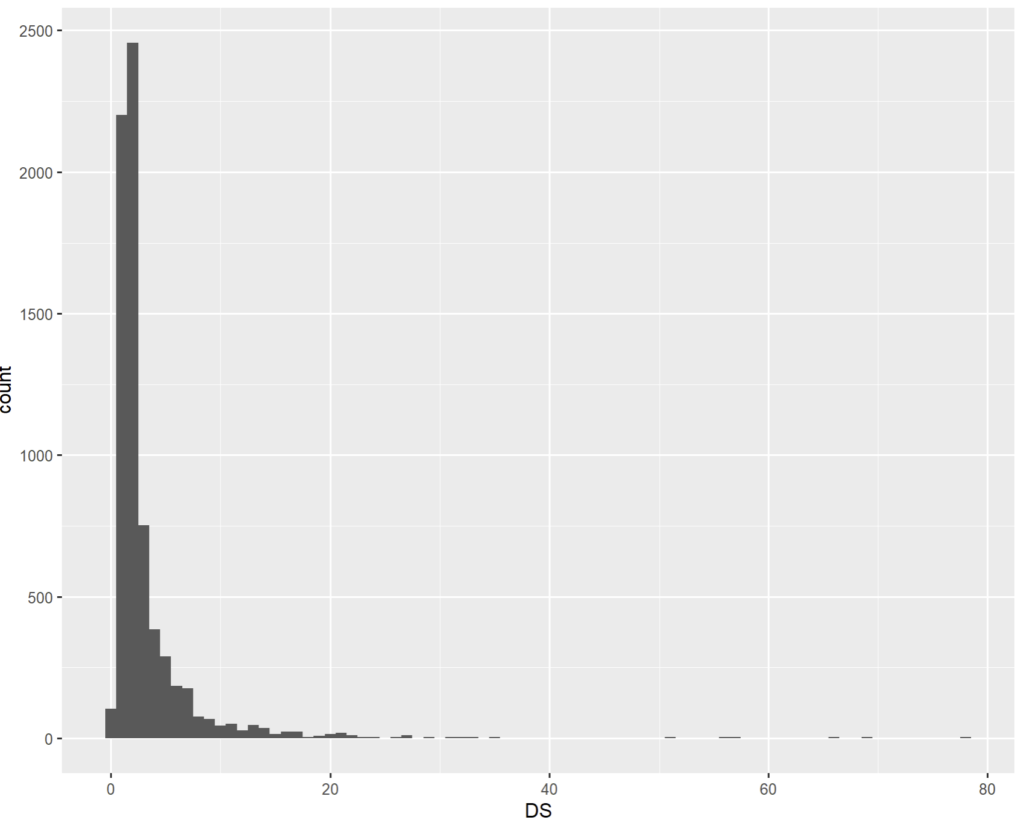
Le même avec une résolution de 1 jour via un geom_histogram() par exemple.
exhaustif vs parcellaire
On peut utiliser d’autres termes comme obligatoire/non-obligatoire. Le critère est de savoir si la donnée doit être fixée dans le vecteur ou inversement si NA ou une valeur de même signification est autorisée.
Les champs principaux du RSS sont obligatoires, mais par exemple le poids de naissance est parcellaire (non-obligatoire) car requis uniquement pour les lignes de RSS concernant la périnatalité.
En filtrant ( %>% filter(!is.na(<champ>))) on peut si besoin produire une version exhaustive sur le sous-groupe
Exemple : Déjà illustré avec le « quantitatif/qualitatif »
naturellement ordonné vs arbitrairement ordonné vs non-ordonné
il s’agit-là de la « classabilité » au sein d’un vecteur.
Une date d’entrée (DENT) est classable et naturellement ordonnée : le 5 février suit toujours le 4 février, etc… l’implémentation en R d’une classe Date définit nativement cet ordre. Bien sûr, il faut gérer les années bissextiles mais cela ne change pas l’ordonnancement global.
C’est le cas de toutes les données numériques représentées par leur valeur directe (DS, valorisation, etc.).
Inversement, il n’y a pas d’ordre de classement entre les différents modes d’entrées (0 – 6 – 7 – 8) bien que ce soient majoritairement des chiffres (et N). Idem pour les GHS. Il est alors souvent non pertinent de laisser l’ordre naturel de classement et privilégier d’autres arrangements.
Exemple :
Pour reprendre notre graphique des CMD (ci dessus), la présentation pourrait être encore plus claire en classant les barres (donc les CMD) par effectif. Ainsi :
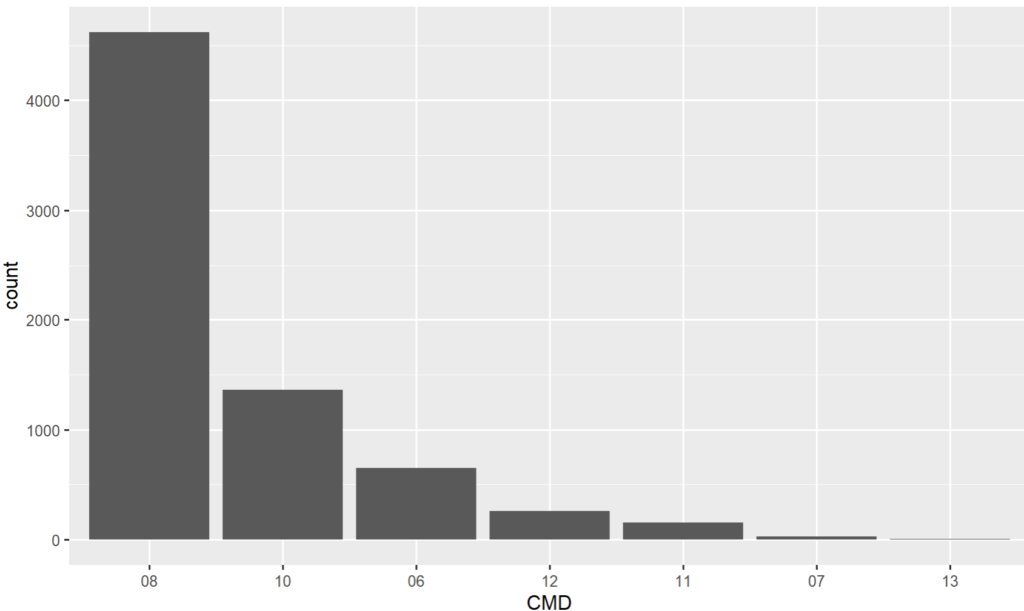
Ce qui permet de visualiser d’un coup d’œil le « classement » des CMD.
Il est possible d’imaginer un vecteur qu’on pourrait arbitrairement ordonner comme le niveau de SEVérité (par exemple, en apparentant A, B, C, D à un niveau de 1 à 4, J et T à 0, Z à 1, à vous de choisir l’échelle que vous jugez pertinente)
Quelques exemples de champs et leurs caractères
| Champ | qualitatif/quantitatif | discret/continu | exhaustif/parcellaire | ordonné |
| GMH | qualitatif | discret | exhaustif | partiel arbitraire (sur la sévérité) |
| Durée de séjour | quantitatif | continu (jour) | exhaustif | naturellement |
| RAAC | qualitatif | discret | parcellaire | non ordonné |
| Poids de naissance | quantitatif | continu (gr) | parcellaire | naturellement |
| GHS | qualitatif | discret | exhaustif (sauf erreur de groupage) | non ordonné |
| valorisation | quantitatif | continu (cents) | exhaustif (sauf erreur de groupage) | ordonné |
| DP | qualitatif | discret | exhaustif | non ordonné |
| DR | qualitatif | discret | parcellaire | non ordonné |
C’est tout pour aujourd’hui. Dans les articles suivants nous allons détailler quelques graphiques ggplot2 et les données qui leur sont adaptées.