
Pour débuter nous allons réaliser des graphiques analysant deux variables +/- corrélées. Le but est d’illustrer quelques angles d’approche, moyen d’affiner ou de souligner certains traits.
Préambule
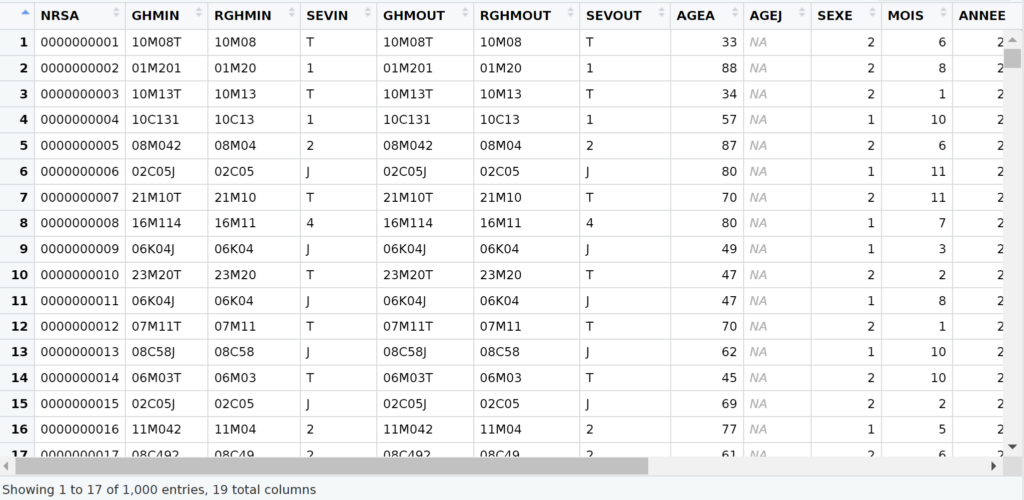
Pour travailler, il va nous falloir des données. Nous allons nous baser sur un jeu de données de 1000 lignes que j’ai généré et exporté vers un .csv. Ainsi si vous utilisez le même code que moi, vous devriez obtenir exactement les mêmes résultats.
Le format est, en termes readr-ien, un csv2. Il faut donc le charger dans R par un
library(readr)
rsa <- read_csv2("extrait_RSA.csv")
L’afficher dans un onglet de RStudio devrait donner :
Pour la lisibilité et la facilité de manipulation nous aurons aussi besoin de dplyr :
library(dplyr)
et bien sûr de ggplot :
library(ggplot2)
Analyser 2 variables dénombrables
Première étape : se poser la question
Pour ce premier exemple, notre question sera « Y-a-t il une relation entre l’âge et la durée de séjour ? »
Préparer les données
Les données de ce premier exemple sont déjà prêtes dans le jeu de données : AGEA et DS.
Pour anticiper nous allons calculer l’effectif mais nous l’utiliserons en temps et en heure.
rsa_modifie <- rsa %>% group_by(AGEA,DS) %>% summarise(n=n())
(qui peut aussi s’écrire rsa %>% count(AGEA,DS))
Choisir le type de graphique
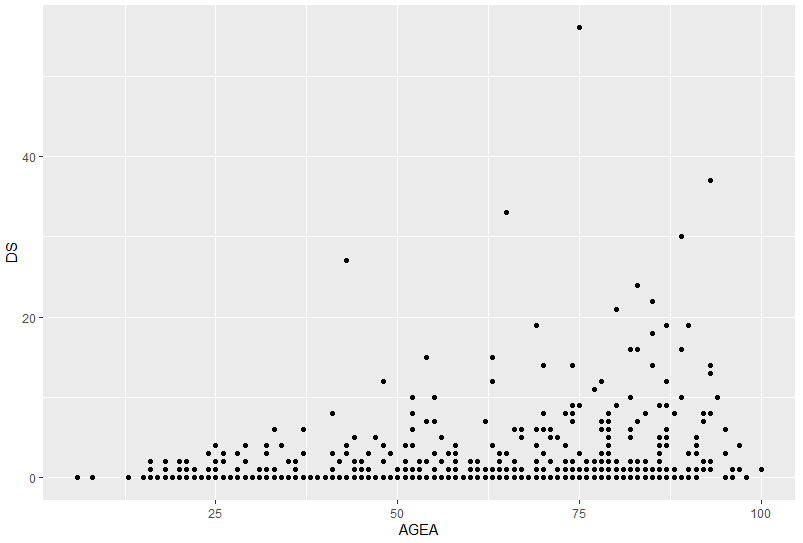
En première tentative, le nuage de point (geom_point()) semblerait un bon compromis. Il dessine un point pour chaque ensemble de coordonnées présente dans le jeu de données.
La granularité intrinsèque des données (l’unité est l’année pour l’âge et le jour pour la DS, elles sont donc discrètes) est cependant visible si nous les utilisons telles quelles :
ggplot(rsa) + geom_point(aes(x = AGEA, y = DS))
qui nous donne des points bien alignés et possiblement… superposés :
En effet, nous ne voyons pas la fréquence de chaque point. Pour cela, nous pouvons ajouter un peu de « jitter » (c’est à dire ajouter un peu d’aléatoire afin que les points ne se superposent pas trop) :
ggplot(rsa) + geom_point(aes(x = AGEA, y = DS), postion = "jitter")
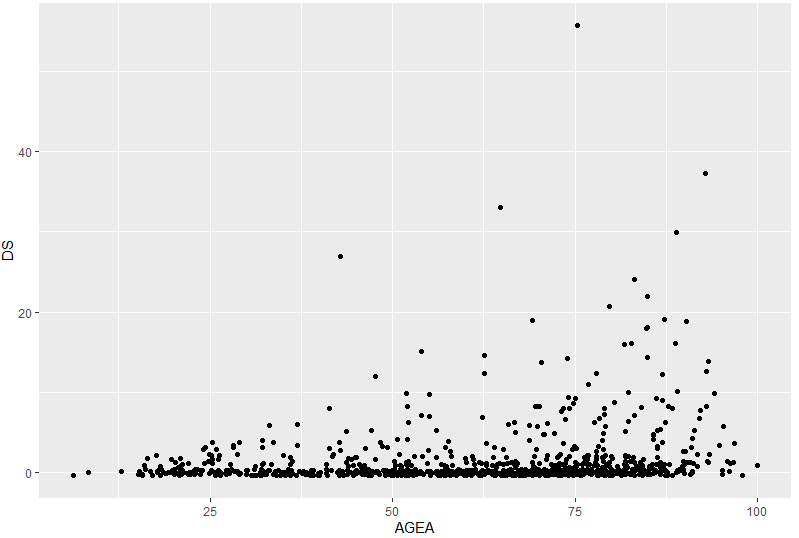
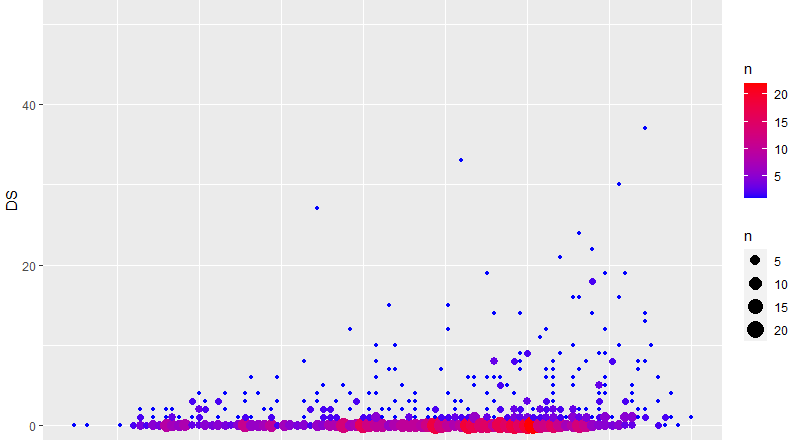
Nous dévoilons ainsi la plus forte concentration sur les séjours courts (c’est normal, nous n’avons pas enlevé l’ambulatoire/HDJ ou l’UHCD). Mais nous pouvons faire mieux, utiliser une 3ème variable, le nombre d’observations. Nous pouvons la créer :
rsa_modifie <- rsa %>% count(AGEA,DS)
#qui est la même chose que
rsa_modifie <- rsa %>% group_by(AGEA, DS) %>% summarise(n = n())
et nous précisons dans l’aes()comment afficher cette variation :
Nous pouvons par exemple faire varier la taille du point :
ggplot(rsa_modifie) %>% geom_point(aes(x = AGEA, y = DS, size = n))
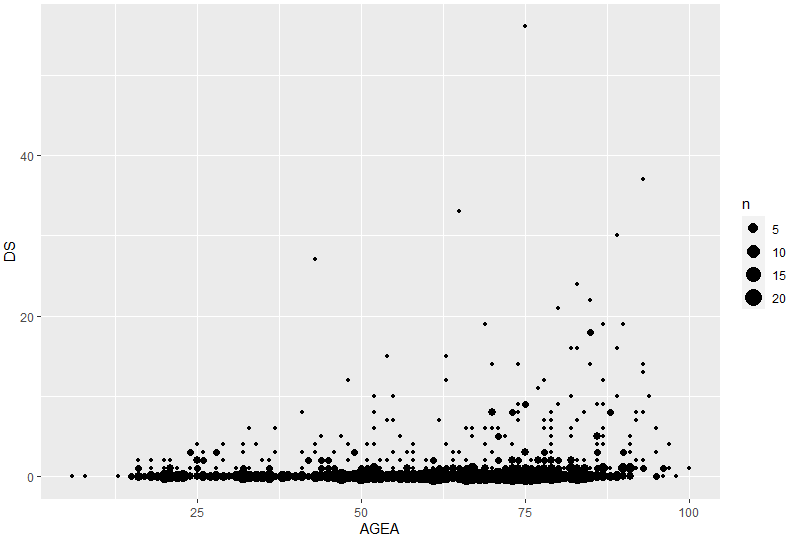
Note:
Il existe une version « courte » orientée statistique de cet appel via :
ggplot(rsa) + stat_sum(aes(x = AGEA, y = DS))
qui donne exactement le même graphe
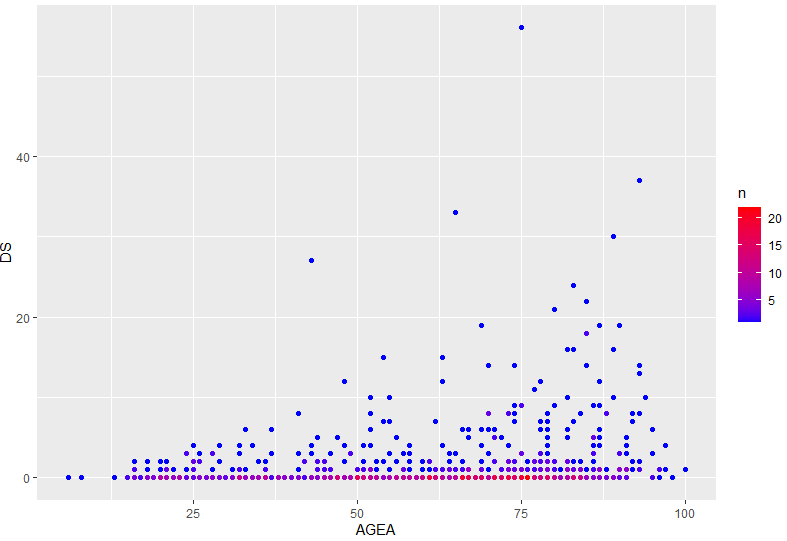
Ou sa couleur :
ggplot(rsa_modifie) +
geom_point(aes(x = AGEA, y = DS, color = n)) +
scale_color_gradient(low = "blue", high = "red")
Et bien sûr nous pourrions faire les deux (je vous laisse deviner la syntaxe) :
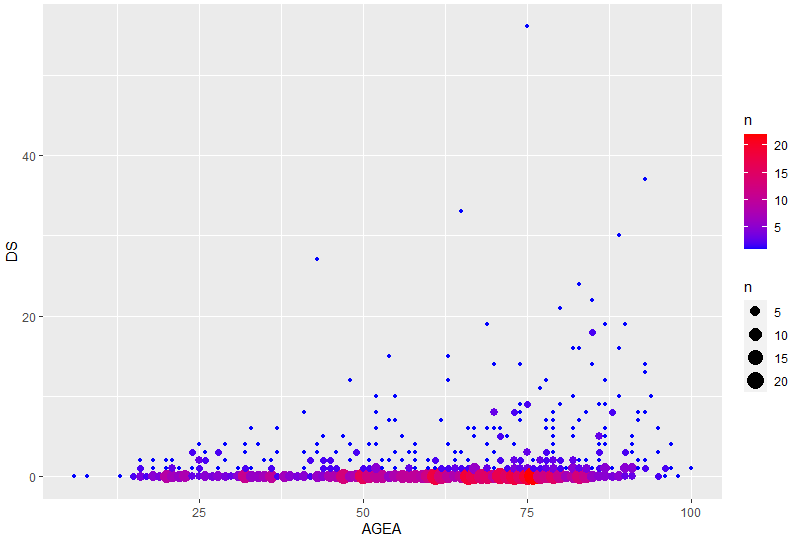
Dans le code ci-dessus, le scale_color_gradient() permet de personnaliser les couleurs via un dégradé allant de low= à high=. D’autres possibilités existent, nous les verrons un jour prochain (mais vous pouvez aussi chercher vous même).
D’autres affichages sont possibles :
La heatmap grâce à
ggplot(rsa_modifie) +
geom_bin2d(aes(x = AGEA, y = DS), binwidth = 1) +
scale_fill_gradient(low = "blue", high = "red")
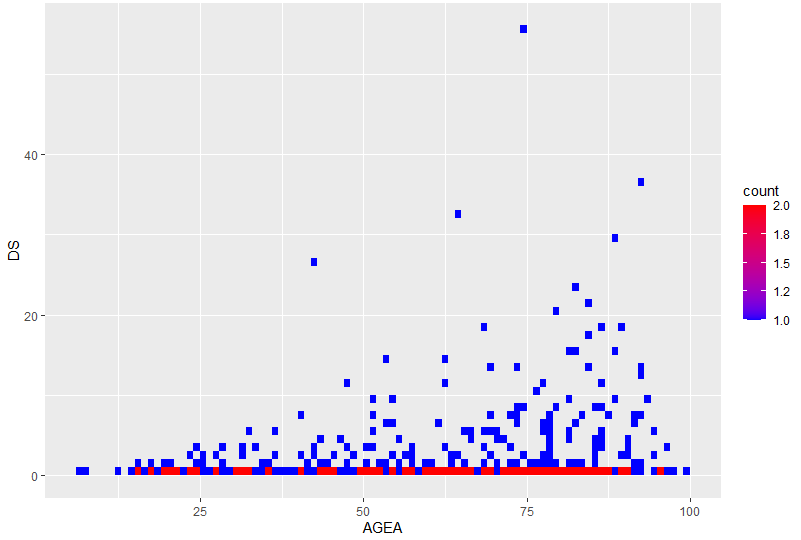
A noter que nous devons définit le gradient de couleur de remplissage (_fill_) et non de couleur de point (_color_) pour adapter l’apparence car dans une heatmap, nous colorons le contenu de cases et non un objet unidimensionnel comme un point.
Nous pouvons aussi utiliser un boxplot (diagramme en boite en français, en anglais on dit aussi box with whiskers (boite à moustaches) ).
Celui-ci est en lui-même une analyse mathématique des données et nécessite que l’on utilise une donnée discrète sur un axe.
Pour utiliser un tel graphique, il faut comprendre la représentation d’une boite unitaire :
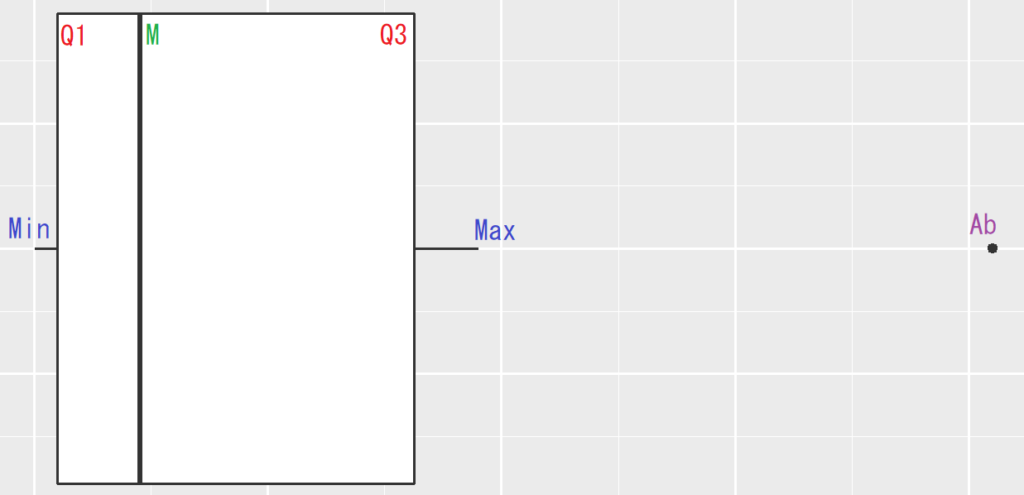
Chaque boite représente 5 caractéristiques du jeu de données :
- M : est la médiane, c’est à dire que la moitié des observations est en dessous et l’autre moitié au dessus (à ne pas confondre avec la moyenne qui se base sur les valeurs du jeu de données)
- Q1 et Q3 : représentent les 1er et 3ème quartiles, c’est à dire que 25% des observations se trouvent sous Q1, 25% entre Q1 et M, 25% entre M et Q3 et 25% au dessus de Q3.
- Min et Max représentent les limites théoriques du jeu si celui-ci était homogène. Ils sont basés sur le calcul :
- Min = Q1 – 1,5 x (Q3 – Q1)
- Max = Q3 + 1,5 x (Q3 – Q1)
- Les points dessinées au delà (Ab) sont les valeurs « Aberrantes », c’est à dire celles qui se trouvent au delà de Min et Max tels que calculés ci-dessus. Elles correspondent grosso-modo à un contrôle d’incohérence avec le reste du jeu de données >98-99% (si la donnée suivait une loi normale, cela voudrait dire un écart de la moyenne supérieur à 2,7 écarts-types).
Pour être complet, (Q3 – Q1) est appelé « Écart Inter Quartile » (IQR en anglais) et illustre la dispersion du jeu de données.
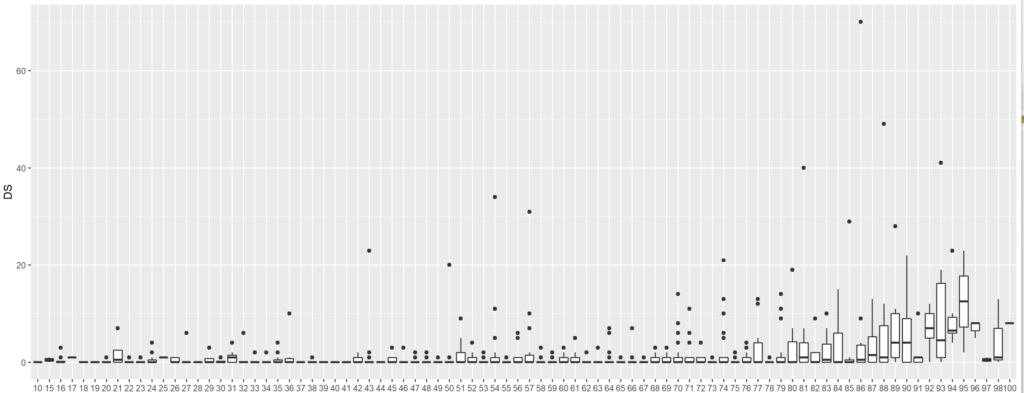
Notre jeu de données donne donc :
ggplot(rsa) + geom_boxplot(aes(x = as.factor(AGEA), y = DS))
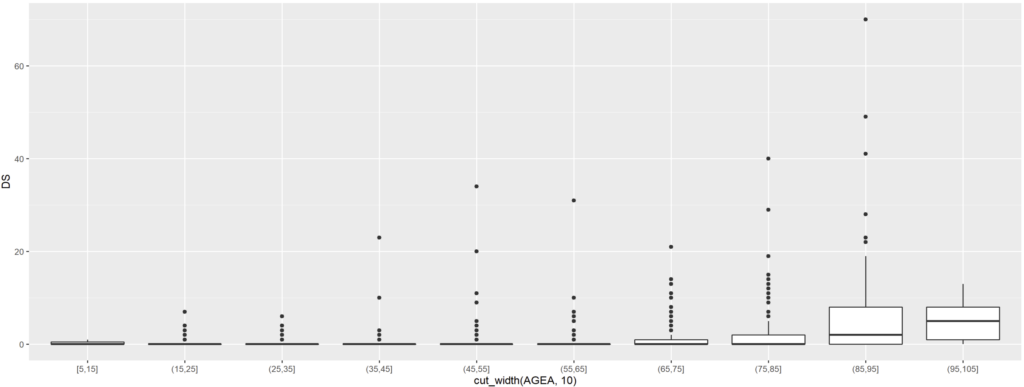
ou si on regroupe un peu les données du jeu pour limiter les tranches d’âge à représenter :
ggplot(rsa) + geom_boxplot(aes(x = cut_width(AGEA, 10), y = DS))
que l’on peut d’autant mieux visualiser en échelle logarithmique (d’autant plus que cela ignore les DS=0) :
ggplot(rsa) + geom_boxplot(aes(x = cut_width(AGEA, 10), y = DS)) + scale_y_log10()
Warning messages:
1: Transformation introduced infinite values in continuous y-axis
2: Removed 710 rows containing non-finite values (stat_boxplot).
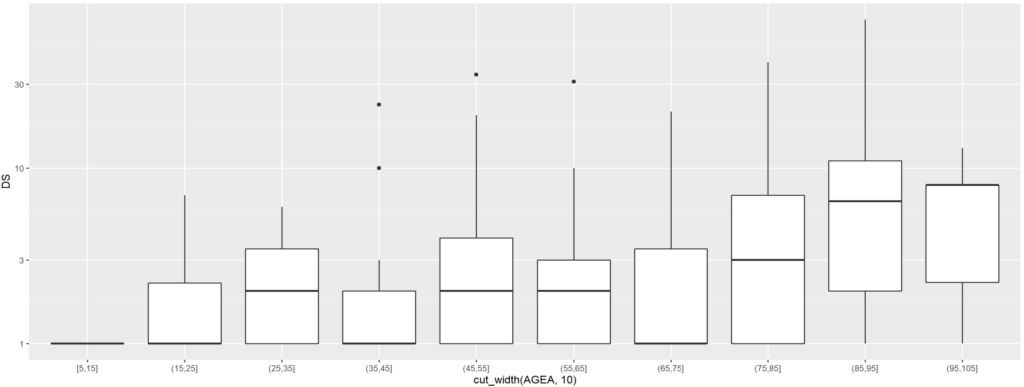
Au final, ce type de visualisation est pertinent car la valeur de chaque point en lui-même ne l’est pas tant que cela, cependant il serait possible de superposer à la DMS. Je vous laisse expérimenter, prévenez-moi en commentaire si vous n’y arrivez pas.
Exercice
Pour vous entraîner, essayez de faire le même type d’analyse en vous limitant aux séjours>0jours (bien plus pertinent pour étuder l’occupation des lits de l’établissement), ou à certaines CMD ou GHM. Essayez de comparer, par exemple, les hommes et les femmes…
Conclusion
J’espère que cet article vous a donné envie d’explorer plus avant les représentations graphiques directes, indirectes et descriptives de vos jeux de données. Nous continuerons les prochaines fois.