
Dans les articles précédents nous avons utilisé kableExtra pour personnaliser une table pour l’afficher puis modifié ses entêtes de colonnes. Aujourd’hui nous voulons ajouter une ligne de résumé.
Mais kableExtra ne sait pas faire cela nativement. Il va falloir programmer cette fonction.
Le jeu de données sources
Comme support, comme souvent, je vais prendre mon RSA d’exemple mais vous pouvez prendre le votre en le découpant vous-même.
Le but est de récupérer un jeu de données comportant au moins les champs MOIS, ANNEE, AGEA (l’âge en années), le SEXE et DS (la durée de séjour)
Que voulons nous étudier ?
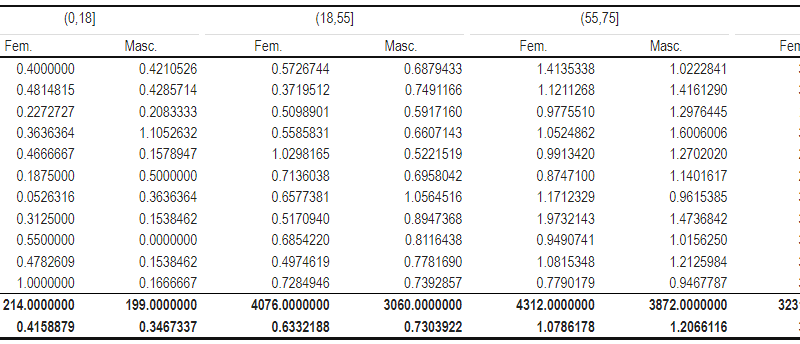
Je voudrais arriver dans un premier temps à un tableau ainsi :
Il représente par mois et année, la DMS en fonction du sexe et de la tranche d’âge et la dernière ligne est la DMS pour les groupes et sous-groupe sur toute la période.
Préparer les données
Dans un premier temps, nous améliorer l’expressivité des données dans une nouvelle table calculée que je vais appeler t :
t <- RSA %>%
mutate(cAGE = cut(AGEA, c(0, 18, 55, 75, Inf), right = TRUE),
SEXE = case_when(
SEXE == 1 ~ "Masc.",
SEXE == 2 ~ "Fem.",
SEXE == 3 ~ "Ind."
))
# soyons clairs, SEXE = 3 ne devrait pas être fréquente (nourisson de moins de 3 mois)Vous êtes libres de modifier les limites et le nombre des catégories d’âge à votre convenance bien sûr ou de les renommer (avec par exemple cut(AGEA,c(0,18,55,75,Inf),labels = c("Enfant","Adulte","Boomer","Ainé"),right=TRUE))
Nous construisons ensuite deux tables par pivot et nous les collons l’une à l’autre :
t1 <- t %>% group_by(cAGE, ANNEE, MOIS, SEXE) %>% summarise(DMS = mean(DS)) %>% pivot_wider(names_from = c(cAGE, SEXE), values_from = DMS)
#et
t2 <- t %>% group_by(cAGE, SEXE) %>% summarise(DMS = mean(DS)) %>% pivot_wider(names_from = c(cAGE,SEXE), values_from = DMS)
t3 <- bind_rows(t1,t2)Nous avons alors un jeu de données comportant les données et une ligne finale comportant la DMS de l’ensemble du jeu. Il ne nous reste plus qu’à…
Mettre en forme
Tout d’abord, il nous faut passer la table dans kable()
Puis nous pouvons séparer les entêtes avec header_separate() (rappel « _ » est le séparateur par défaut de pivot_wider() :
t3 %>% kable %>% header_séparate(sep="_")et faire une mise en forme par défaut avec kable_classic() (vous pouvez prendre celui que vous voulez bien sûr) :
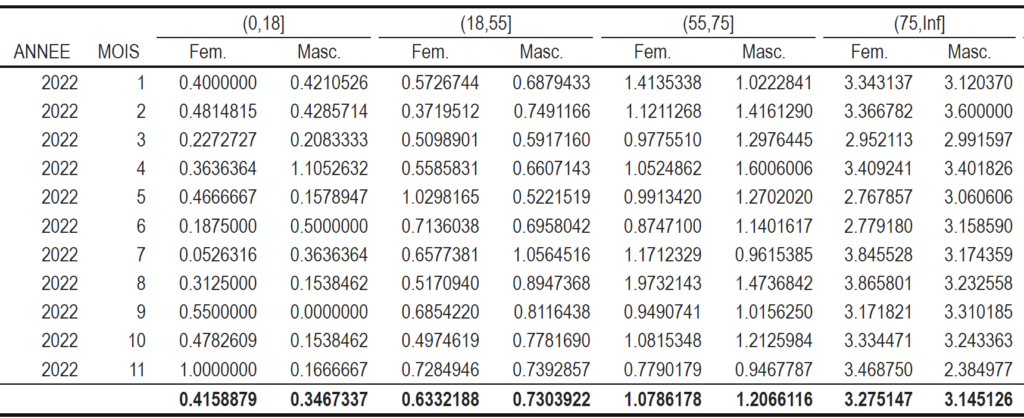
... %>% kable_classicAinsi vous obtenez un aspect comme celui-ci :
Il ne nous reste plus qu’à mettre un petit peu de mise en forme du bas du tableau pour améliorer la visibilité. Nous allons pour cela utiliser row_spec().
row_spec()
row_spec permet de personnaliser les cellules d’une ligne donnée de l’objet kable qui lui est passé en 1er argument. Le 2ème argument est l’index absolu de la ligne à modifier (portant le nom row= si vous voulez le renseigner nommé) et les suivants définissent les paramètres d’aspect. En voici la liste :
bold=(par défaut FALSE) met le texte en grasitalic=(par défaut FALSE) met le texte en italiquemonospace=(par défaut FALSE) utilise une police à chasse fixeunderline=(par défaut FALSE) souligne le textestrikeout=(par défaut FALSE) barre le textecolor=(par défaut NULL) définit la couleur du textebackground=(par défaut NULL) idem que color= mais pour le fondalign=(par défaut NULL) change l’alignement du textefont_size=(par défaut NULL) modifie la taille de policeangle=(par défaut NULL) change l’angle d’écriture du texteextra_css=(par défaut NULL) ajoute des éléments de CSS pour les sorties HTMLhline_after=(par défaut FALSE) pour LaTeX uniquement, ajoute une ligne horizontale en dessousextra_latex_after=(par défaut NULL) ajoute du code LaTeX après
Bien sûr certaines options pour HTML n’ont pas de sens en LaTeX et vice-versa.
Ici nous voulons mettre la ligne en gras donc nous ajoutons bold = TRUE. Cependant il faut déterminer la ligne. C’est simple car c’est la ligne qui suit notre jeu de données t1. Il suffit donc de faire :
... %>% row_spec(t1 %>% nrow + 1,bold=TRUE) %>%
row_spec(t1 %>% nrow,extra_css = "border-bottom:black solid 1px;")(j’en ai profité pour ajouter la ligne de séparation pour le HTML en rajoutant un élément de style CSS sur la dernière ligne de données de la 1ere table)
Si par exemple vous vouliez généraliser en cas de pied de tableau à plusieurs lignes, il faudrait remplacer la valeur de row= par un range :
... %>% row_spec((t1 %>% nrow + 1):(t1 %>% nrow + t2 %>%nrow),bold=TRUE) %>%
row_spec(t1 %>% nrow,extra_css = "border-bottom:black solid 1px;")Bonus : Emballons le tout
Ce genre de code pourrait être intéressant à réutiliser, faisons-en une fonction que nous appellerons kable_resume_apres() par exemple. (Notez que comme souvent, c’est une version possible de l’implémentation, une autre personne pourrait spontanément l’écrire autrement)
kable_resume_apres <- function(data, resume, kable_format, sep="_"){
# On verifie que nous avons bien une table de résumé.
# Le reste des fonctions feront apparaitre les anomalies.
if(is.data.frame(resume)) {
# A-t-on au moins 1 ligne dans le résumé
if (nrow(resume)>0) {
# test pour vérifier que toutes les colonnes du résumé sont dans data. C'est une erreur fatale.
if(!all((resume %>% names) %in% (data %>% names))) stop("Les colonnes ne correspondent pas entre les données et le résumé.\ntoutes n'ont pas à être présentes, mais aucune n'est autorisée en plus.")
tmp <- bind_rows(data,resume)
tmp %>% kable %>%
header_separate(sep = sep) %>%
kable_format %>%
row_spec((data %>% nrow + 1):(data %>% nrow + resume %>%nrow),bold=TRUE) %>%
row_spec(data %>% nrow,extra_css = "border-bottom:black solid 1px;")
} else {
# Nous n'avons pas de ligne de résumé.
# Nous n'imprimons que le tableau de données avec un warning
warning("resume= ne contient pas de lignes. Ignoré.")
data %>% kable %>%
header_separate(sep = sep) %>%
kable_format
}
} else {
# Nous n'avons pas de résumé du tout (ou d'un mauvais type de données).
# Nous n'imprimons que le tableau de données avec un warning
warning("resume= n'est pas un data.frame. Ignoré.")
data %>% kable %>%
header_separate(sep = sep) %>%
kable_format
}
}
# Nous l'exécutons par :
> kable_resume_apres(t1, t2, kable_classic)Notez que nous passons kable_classic comme paramètre et non kable_classic() car nous passons la fonction complète afin de pouvoir l’utiliser dans le code, pas le résultat de l’appel à la fonction (ce qui n’aurait aucun sens).
Il existe une limitation à cette méthode. Le type de données de chaque colonne ne peut/doit pas changer sous peine de générer des erreurs, ou pire casser l’aspect final 🙂 . Une colonne numérique dans data= doit donc être une colonne numérique dans resume=. Voici un exemple de code qui permet de faire « au mieux » sans y passer trop de temps :
#On crée le résumé en extrayant l'effectif et la DMS
> t2 <- t %>% group_by(cAGE, SEXE) %>%
summarise(n = n(), moy = mean(DS)) %>%
# ici on s'assure d'avoir une table "à plat"
pivot_longer(cols = c(n, moy)) %>%
pivot_wider(names_from = c(cAGE, SEXE), values_from = value) %>%
# pour mieux repivoter les données pour les rendre compatible
rename(ANNEE = name)
# enfin on renomme "name" en "ANNEE" pour remplir la colonne en question
# Lors de l'appel de kable_resume_apres(), on modifie au vol le format de "ANNEE"
> kable_resume_apres(t1 %>% mutate(ANNEE=as.character(ANNEE)),t2 ,kable_classic)Et cela nous donne :
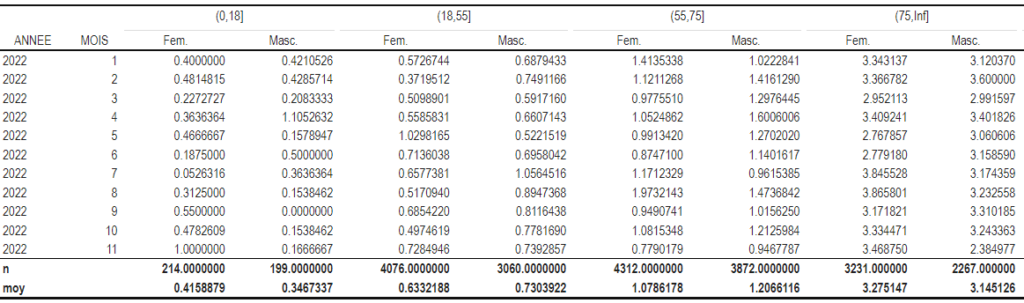
Pas si mal pour quelques lignes…
Conclusion
Par cet article, vous avez pu apprendre à utiliser kableExtra de façon détournée pour ajouter un pied de table car cela n’est pas prévu. Cela nous a permis de voir un peu de manipulation/transformation de données et de dataframes pour arriver à nos fins.
La prochaine fois, nous continuerons avec une autre fonctionnalité de kableExtra. A bientôt.