

Nous avons vu dans l’article https://pmsidansr.senis.org/2023/01/02/le-typage-des-variables/ les différents types de base des variables.
R étant un langage pratique, il existe plus que ces quelques types et nous allons en voir certains progressivement. Pour commencer, nous allons parler des factors.
Dans d’autres langages.
Pour comprendre, si vous programmez déjà, ce concept existe plus ou moins, dans d’autres langages sous un autre nom. En C, il s’agirait d’une instanciation d’un enum, en Python idem (sous réserve d’inclure la librairie du même nom). La grosse différence est qu’un factor est mutable (on peut changer son contenu ou sa définition).
Pour les autres, il s’agit d’une table de correspondance entre 1 donnée (appelée « level » et un index numérique. La présence dans le factor d’un level étant unique. Il s’agit d’un format optimisé de stockage d’une donnée discrète (par opposition à continue).
> factor(c("A","B","C"))
[1] A B C
Levels: A B C
et voici la représentation interne :
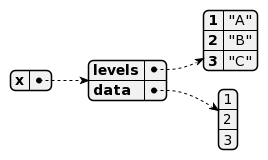
Un exemple pratique valant mieux qu’un long discours. Dans le RSS, le champ UM accepte les chaines de caractères mais la liste des UM est limitée (dans notre exemple de UM1 à UM5). Cela pourrait donc s’écrire sous forme de factor :
#On crée un faux RSS avec UM contenant une chaine de caractères:
> RSS <- data.frame(NRUM = sample(1:7), UM = c("UM1", "UM1", "UM5", "UM4", "UM2", "UM4", "USC"))
> RSS$UM
[1] "UM1" "UM1" "UM5" "UM4" "UM2" "UM4" "USC"
> typeof(RSS$UM)
[1] "character"
> class(RSS$UM)
[1] "character"
# UM est un vecteur de chaines
> RSS$NouvUM <- as.factor(RSS$UM)
> RSS$NouvUM
[1] UM1 UM1 UM5 UM4 UM2 UM4 USC
Levels: UM1 UM2 UM3 UM4 USC
# NouvUM est un factor
> typeof(RSS$NouvUM)
[1] "integer"
> class(RSS$NouvUM)
[1] "factor"
Comparons la représentation interne entre le vector source et le factor résultant (pour être exhaustif, j’ai mis tout RSS) :
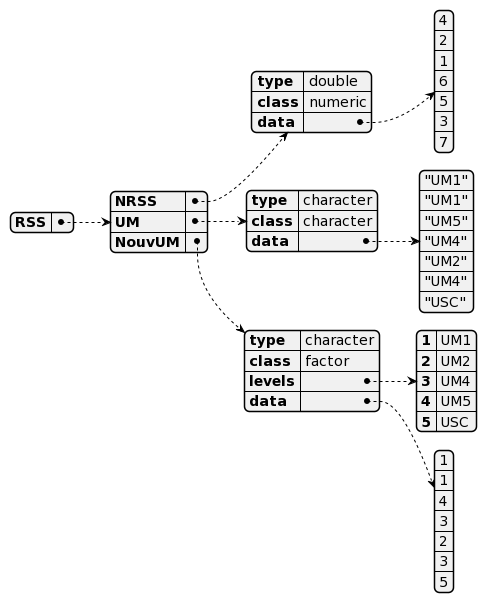
L’intérêt des facteurs
Il réside dans une plus grande rapidité de recherche car de façon interne il s’agit d’une structure basée sur des nombres entiers plus facile à indexer que l’on peut voir en convertissant via as.numeric() :
> as.numeric(RSS$NouvUM))
[1] 1 1 4 3 2 3 5
Changer UM5 en BLA puis en USC peut se faire à grande échelle en modifiant le libellé (level), ainsi plutôt que de devoir rechercher et modifier tous les valeurs elles-mêmes :
> levels(RSS$NouvUM)
[1] "UM1" "UM2" "UM4" "UM5" "USC"
> levels(RSS$NouvUM)[4]
[1] "UM5"
> levels(RSS$NouvUM)[4]<- "BLA"
> RSS$NouvUM
[1] UM1 UM1 BLA UM4 UM2 UM4 USC
Levels: UM1 UM2 UM4 BLA USC
> levels(RSS$NouvUM)[4]<- "USC"
> levels(RSS$NouvUM)
[1] "UM1" "UM2" "UM4" "USC"
> RSS$NouvUM
[1] UM1 UM1 USC UM4 UM2 UM4 USC
Levels: UM1 UM2 UM4 USC
La dernière modification a contracté la liste des libellés (USC étant déjà dans la liste initiale). Cpendant cette réduction n’est pas automatique, par exemple en cas de subsetting :
# On crée un factor contenant 5 fois les 10 premières lettres de l'alphabet
> x <- as.factor(rep(LETTERS[1:10],5))
> x
[1] A B C D E F G H I J A B C D E F G H I J A B C D E F G H I J A B C D E F G H I J A B C D E F G H I J
Levels: A B C D E F G H I J
# On supprime les occurrences du "G"
> x[x!="G"]
[1] A B C D E F H I J A B C D E F H I J A B C D E F H I J A B C D E F H I J A B C D E F H I J
Levels: A B C D E F G H I J
# Mais "G" est encore dans les levels, alors qu'il n'est plus dans les variables.
# Seul un repassage par factor() corrigerait l'anomalie
> factor(x[x!="G"])
[1] A B C D E F H I J A B C D E F H I J A B C D E F H I J A B C D E F H I J A B C D E F H I J
Levels: A B C D E F H I J
Les désavantages des facteurs
Le gain en vitesse de traitement se fait en échange d’une dépendance à une liste fermée de valeurs. Bien sûr il est toujours possible de rajouter des facteurs à la création ou lors de la manipulation mais le processus de création ne peut par exemple garantir que levels(…)[2] sera constant au cours de lancements successifs avec des données similaires mais pas strictement identiques.
A la création, l’index (numérique) est créé croissant en fonction de l’ordre des données. Lorsqu’on renomme un level avec un nom inexistant, l’ordre n’est pas modifié même si ce n’est pas l’ordre alphabétique. Mais si on renomme avec un nom d’index existant, la liste des levels est compressée et tous les index suivants sont décalés.
Ce qui peut être peu gênant avec des données symboliques (alphanumériques ayant une signification indépendante de leur ordre) peut poser problème si appliqué sur des données numériques entières. Notez le couac d’interprétation ci dessous :
> x <- as.factor(c(1, 2, 3, 4, 5, 6, 7))
> > x
[1] 1 2 3 4 5 6 7
Levels: 1 2 3 4 5 6 7
> as.numeric(x)
[1] 1 2 3 4 5 6 7
# Pour l'instant tout va bien
# On change la valeur d'un des index
> levels(x)[3]<-4
> x
[1] 1 2 4 4 5 6 7
Levels: 1 2 4 5 6 7
# L'aspect du factor est inchangé mais...
> as.numeric(x)
[1] 1 2 3 3 4 5 6
# Aïe, la conversion en numérique donne le numéro d'index même si la donnée a été rentrée en tant qu'entier qui devrait être interprété comme un nombre.Bien entendu, il y a une façon d’échapper à cette malédiction en convertissant d’abord le factor en vecteur de chaines (le type sous-jacent des levels est character)
> typeof(levels(x))
[1] "character"
> as.character(x)
[1] "1" "2" "4" "4" "5" "6" "7"
> as.numeric(as.character(x))
[1] 1 2 4 4 5 6 7 # Cette fois-ci c'est bon !
Cependant, cela est source d’erreur, alourdit la programmation et le traitement si utilisé trop fréquemment, et ne permet pas d’écrire un code supportant les 2 types de façon transparente. Il faut alors passer systématiquement par un test préalable. On pourrait par exemple créer une fonction :
as.numeric_f <- function(x) {
if(is.factor(x))
as.numeric(as.character(x))
else
as.numeric(x)
}
#ou en version minimaliste et factorisée :
as.numeric_f <- function(x) as.numeric(
if(is.factor(x)) as.character(x) else x
)
En pratique PMSI
De mon côté, j’ai pris le parti de ne pas utiliser les factors dans le traitement du PMSI même si de nombreux champs s’y prêteraient pour éviter ces effets de bord (sur un petit test sans prétention – remplacement d’une chaine parmi 12 sur un factor de 12 millions de valeurs fait économiser… une demi seconde par rapport à un traitement en vector…).
Cependant, il faut connaitre l’existence de ce type de données pour ne pas se retrouver devant un fonctionnement « bizarre » et pouvoir l’analyser. Il est de toute façon possible de créer en cas de besoin, « à la volée », un factor via as.factor() à partir d’un autre vecteur.
La prochaine fois, nous aborderons les listes simples.