

Dans les articles précédents nous avons appris à transposer les retraitements SQL standards en R. Cependant, il manque quelque chose d’essentiel : R travaille avec des objets en mémoire, c’est à dire chargés dans des data.frames, vecteurs, listes etc. alors que vos données sont probablement rangées bien au chaud dans une base de données. Allez-vous devoir exporter manuellement des giga-octets de fichiers CSV, parquet ou autre pour pouvoir faire vos petits calculs ?
Que nenni car entre en scène une extension de dplyr : dbplyr !
Qu’est ce que dbplyr ?
dbplyr est un sous-projet parallèle à dplyr qui est désormais intégré. Son rôle est de proposer une couche d’abstraction pour tout simplement utiliser au maximum la syntaxe dplyr afin de manipuler directement une ou des bases de données.
dbplyr fonctionne autant que possible de façon transparente pour migrer les données de ou vers la base de données afin de décharger une partie du travail du poste local.
En pratique, dans la majorité des cas, dbplyr vas transformer un pipline dplyr en requête SQL pour la faire tourner sur le serveur de base de données et ensuite importer le résultat pour continuer le traitement localement.
C’est un peu confus tout ça !
Je suis d’accord et c’est pour cela que je vous propose de commencer d’emblée par la mise en oeuvre.
Premier problème, avoir accès à une base de données
Pour pouvoir étudier un exemple réel, il nous faut des données réelles. Je ne peux malheureusement pas deviner les données que chaque lecteur a ou n’a pas à disposition.
Je vous ai donc concocté un pseudo-DPI que vous allez trouver sous un format bien connu : SQLITE.
SQLITE est un serveur embarqué de base de données qu’il est possible de charger à la volée dans un programme et qui sauvegarde les données dans un unique fichier qu’il va simplement falloir télécharger :
Les données en particulier nominatives fournies dans ce fichier sont totalement fictives mais faites pour avoir l’air réelles, ne vous inquiétez pas. Aucune réelle donnée patient n’est divulguée.
Les librairies nécessaires
Pour notre exercice, nous allons avoir besoin de certaines librairies qu’il faudra ajouter si nécessaire :
- dplyr, bien sûr
- DBI, la couche d’abstraction de base de données
- Rsqlite, la couche spécifique au format SQLITE
Il nous faut aussi tidyr pour illustrer un retraitement en R
Si nous avions tenté de nous connecter à une base Oracle, MySQL/MariaDB, PostgreSQL, etc. il aurait fallu alors charger la librairie spécifique (qu’on appelle backend). Vous avez sur la droite la liste des moteurs de base de données officiellement supportés par dbplyr. Les principales y sont. De plus avec ODBC, cela ouvre – si vous êtes sur une machine adaptée- tous les drivers génériques qui pourraient y être liés.
Dans notre cas, nous voulons SQLITE donc c’est bon !
Par ailleurs, la dernière ligne stipule Teradata qui est le moteur de base de données qui a été déployé l’année dernière sur la plateforme d’accès aux données de santé de l’ATIH. Et cette dernière a décidé de migrer totalement ses bases, applications et webapps de reporting de SAS vers R/Teradata ! L’avenir du requêtage national du PMSI sera donc à portée de vos doigts à la fin de cet article.
Se connecter à un fichier SQLITE
Une fois le fichier récupéré et enregistré sur votre disque (pour ma part, je l’ai dans mon répertoire de travail), il faut s’y connecter.
# Chargeons les librairies
library(tidyr)
library(DBI)
library(RSQLite)
library(dplyr)
# Et connectons-nous
con <- dbConnect(SQLite(),
"dpi_demo.sqlite",
extended_types = TRUE #nécessaire pour les types DATE
)A partir de maintenant, nous pouvons utiliser le contenu de ce fichier. con= est un descripteur qui va permettre à toutes le futures commandes que nous allons appliquer d’interagir avec les tables qui y sont stockées.
Le contenu du fichier d’exemple
Nous pouvons par exemple demander la liste des tables contenues dans le fichier avec la fonction DBI dbListTables() puis leurs colonnes avec dbListFields() :
> dbListTables(con)
[1] "diags" "patients" "rums" "sejours"
> dbListFields(con,"patients")
[1] "NOM" "PRENOM" "DDN" "SEXE" "IPP"
> dbListFields(con,"sejours")
[1] "GHMC" "GHS" "DENT" "DSORT" "IPP" "DS" "NDA"
> dbListFields(con,"rums")
[1] "MENT" "MSORT" "DENT_RUM" "DSORT_RUM" "NRUM" "NDA"
> dbListFields(con,"diags")
[1] "DIAG" "TYPE" "NRUM" "NDIAG"
Comme vous pouvez le voir la structure mime un minuscule « pseudo DPI » avec des SEJOURS, une relation 1-à-plusieurs vers des RUMs, eux-mêmes ayant une relation 1-à-plusieurs vers des DIAGS et chaque séjour dépendant d’un PATIENT (relation plusieurs-à-un).
Attacher des tables
Telles qu’elles ces tables pourraient être chargées « brutalement » en mémoire via dbReadTable() qui charge la totalité de son contenu en mémoire au sein d’un data.frame. Mais ce n’est pas notre but. Nous allons donc définir un lien entre la table dans la base de données et un objet R via tbl() :
patients_tbl <- tbl(con, "patients")
patients_tbl
# Source: table<`patients`> [?? x 5]
# Database: sqlite 3.47.1 [C:\Users\fsenis\Documents\R\atih_demo.sqlite]
NOM PRENOM DDN SEXE IPP
<chr> <chr> <date> <chr> <chr>
1 SUDRE PIERRETTE 1942-10-19 F P000004646
2 MOTTIN ALAIN 1960-09-19 H P000003594
3 ROSTAING PATRICK 1955-08-21 H P000004313
4 LHOTE NOELE 1951-01-02 F P000003113
5 FERCHAUD MIGAEL 1981-04-08 H P000001973
6 NEGRIER JEREMIE 1979-12-19 H P000003669
7 MEYRE MONIQUE 1941-07-22 F P000003468
8 KESKAS MURIELLE 1962-03-14 F P000002723
9 BERRIE GUY 1945-04-17 H P000000490
10 MONCOURRIER GUY 1943-02-01 H P000003530
# ℹ more rows
# ℹ Use `print(n = ...)` to see more rowsComme vous pouvez le voir dans le volet environnement de RStudio, cet objet n’est pas du tout un dataframe :

mais un objet complexe qu’heureusement vous n’avez pas le besoin d’explorer pour l’utiliser :
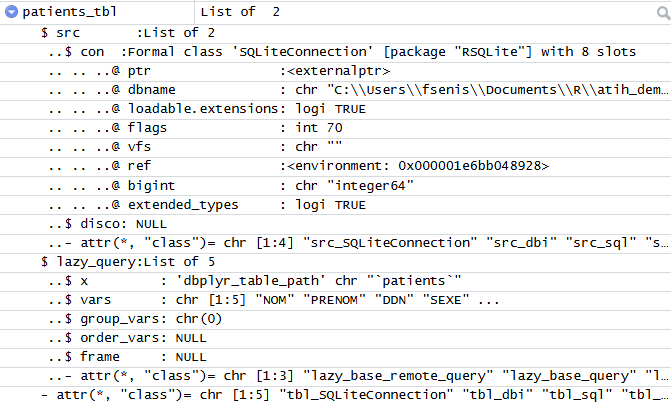
Si vous regarder en détail le résultat de sortie, on repère des différences notables dans la sortie :
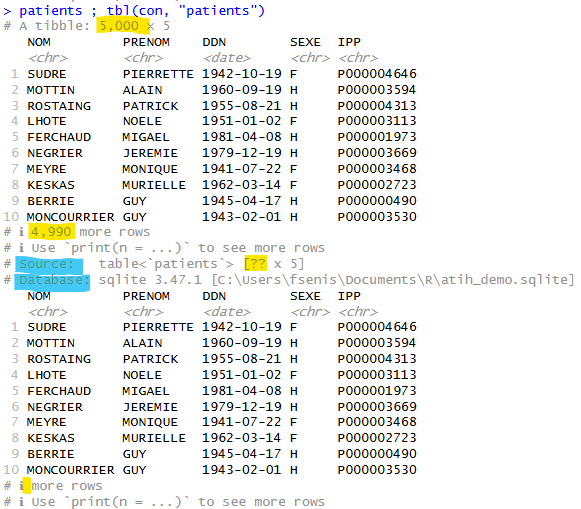
Le dataframe « patients » a un nombre de lignes défini (5000, entièrement chargées en mémoire), tandis que la tbl « patients » ne connait pas sa taille et possède des informations de source en plus. En cas d’appel pour affichage, tbl() va aller chercher un échantillon limité des données dans la base, mais uniquement pour vous faire plaisir.
Si nous voulions récupérer toute la table, nous utiliserions plutôt la fonction DBI dbReadTable() :
> dbReadTable(con, "patients") %>% as_tibble()
# A tibble: 5,000 × 5
NOM PRENOM DDN SEXE IPP
<chr> <chr> <date> <chr> <chr>
1 SUDRE PIERRETTE 1942-10-19 F P000004646
2 MOTTIN ALAIN 1960-09-19 H P000003594
3 ROSTAING PATRICK 1955-08-21 H P000004313
4 LHOTE NOELE 1951-01-02 F P000003113
5 FERCHAUD MIGAEL 1981-04-08 H P000001973
6 NEGRIER JEREMIE 1979-12-19 H P000003669
7 MEYRE MONIQUE 1941-07-22 F P000003468
8 KESKAS MURIELLE 1962-03-14 F P000002723
9 BERRIE GUY 1945-04-17 H P000000490
10 MONCOURRIER GUY 1943-02-01 H P000003530
# ℹ 4,990 more rows
# ℹ Use `print(n = ...)` to see more rowsDans ce cas, nous recevons un data.frame qu’on transforme en tibble et nous avons une stricte égalité entre les 2 sorties.
Monter une requête d’extraction
Il faut bien avouer, récupérer la totalité d’une table depuis une base de données est exactement la négation de la raison d’être d’une base de données relationnelle. Au contraire, son but est de n’en extraire que les données pertinentes.
Supposons donc que nous voulions les patients s’appelant « GUY ». En SQL, nous utiliserions :
SELECT * FROM patients WHERE PRENOM = "GUY";Et nous pouvons directement l’appliquer en DBI avec dbGetQuery() :
#attention à la bonne gestion des guillements simplpes et doubles
> dbGetQuery(con, 'SELECT * FROM patients WHERE PRENOM = "GUY";') %>% as_tibble
# A tibble: 29 × 5
NOM PRENOM DDN SEXE IPP
<chr> <chr> <date> <chr> <chr>
1 BERRIE GUY 1945-04-17 H P000000490
2 MONCOURRIER GUY 1943-02-01 H P000003530
3 JACQUET GUY 1938-07-24 H P000002618
4 LACOTE GUY 1947-07-29 H P000002793
5 HERNANDEZ GUY 1931-06-16 H P000002510
6 FOUILLEUL GUY 1937-07-17 H P000002071
7 BASSELFALL GUY 1948-05-11 H P000000338
8 NAVARRO GUY 1943-02-01 H P000003659
9 COURTADEGRANGE GUY 1947-08-13 H P000001287
10 TANGUY GUY 1936-03-15 H P000004666
# ℹ 19 more rows
# ℹ Use `print(n = ...)` to see more rowsMais nous pouvons utiliser la syntaxe dplyr pour construire la requête :
> tbl(con, "patients") %>% filter(PRENOM == "GUY")
# Source: SQL [?? x 5]
# Database: sqlite 3.47.1 [C:\Users\fsenis\Documents\R\atih_demo.sqlite]
NOM PRENOM DDN SEXE IPP
<chr> <chr> <date> <chr> <chr>
1 BERRIE GUY 1945-04-17 H P000000490
2 MONCOURRIER GUY 1943-02-01 H P000003530
3 JACQUET GUY 1938-07-24 H P000002618
4 LACOTE GUY 1947-07-29 H P000002793
5 HERNANDEZ GUY 1931-06-16 H P000002510
6 FOUILLEUL GUY 1937-07-17 H P000002071
7 BASSELFALL GUY 1948-05-11 H P000000338
8 NAVARRO GUY 1943-02-01 H P000003659
9 COURTADEGRANGE GUY 1947-08-13 H P000001287
10 TANGUY GUY 1936-03-15 H P000004666
# ℹ more rows
# ℹ Use `print(n = ...)` to see more rowsNotez que nous sommes toujours en live dans la base de données donc la requête ne connait pas sa taille et renvoit juste un aperçu. Pour récupérer définitivement (et figer) les données, nous avons une dernière action à réaliser : collecter les données avec… collect()
> tbl(con, "patients") %>% filter(PRENOM == "GUY") %>% collect
# A tibble: 29 × 5
NOM PRENOM DDN SEXE IPP
<chr> <chr> <date> <chr> <chr>
1 BERRIE GUY 1945-04-17 H P000000490
2 MONCOURRIER GUY 1943-02-01 H P000003530
3 JACQUET GUY 1938-07-24 H P000002618
4 LACOTE GUY 1947-07-29 H P000002793
5 HERNANDEZ GUY 1931-06-16 H P000002510
6 FOUILLEUL GUY 1937-07-17 H P000002071
7 BASSELFALL GUY 1948-05-11 H P000000338
8 NAVARRO GUY 1943-02-01 H P000003659
9 COURTADEGRANGE GUY 1947-08-13 H P000001287
10 TANGUY GUY 1936-03-15 H P000004666
# ℹ 19 more rows
# ℹ Use `print(n = ...)` to see more rowsMaintenant, si patients_tbl a été initalisé par tbl(con, "patients"), nous pouvons appeler :
> patient_tbl %>% filter(PRENOM == "GUY") %>% collectEt vous avez ici toute la puissance de dbplyr : vous écrivez votre pipeline dplyr mais à base de tbl() et collect() génère le jeu de données résultat. 2 exemples pratiques :
#Quelques valeurs de base définies dans R
cim_sp <- "Z515"
ghm_sp <- c("23Z02Z", "23Z02T")
# les tables de la base de données
patients_tbl <- tbl(con, "patients")
sejours_tbl <- tbl(con, "sejours")
rums_tbl <- tbl(con, "rums")
diags_tbl <- tbl(con, "diags")
# Traitements :
# Séjours en GHM de soins palliatifs ou soins de support
> sejours_tbl %>% filter(GHMC %in% ghm_sp) %>% collect
# A tibble: 613 × 7
GHMC GHS DENT DSORT IPP DS NDA
<chr> <dbl> <dttm> <dttm> <chr> <int> <chr>
1 23Z02T 7991 2019-10-01 14:00:00 2019-10-01 17:20:00 P000003538 0 S000000001
2 23Z02Z 7994 2019-10-03 14:50:00 2019-10-06 15:30:00 P000003249 3 S000000002
3 23Z02Z 7994 2019-10-07 10:39:00 2019-10-20 19:25:00 P000002627 13 S000000003
4 23Z02T 7991 2019-10-07 13:56:00 2019-10-07 17:00:00 P000001893 0 S000000004
5 23Z02T 7991 2019-10-08 09:30:00 2019-10-08 16:00:00 P000003130 0 S000000005
6 23Z02Z 7994 2019-10-09 08:59:00 2019-10-22 08:10:00 P000001346 13 S000000006
7 23Z02Z 7994 2019-10-10 08:48:00 2019-10-14 09:00:00 P000001607 4 S000000007
8 23Z02Z 7994 2019-10-11 11:21:00 2019-10-20 08:00:00 P000002174 9 S000000008
9 23Z02T 7991 2019-10-14 13:25:00 2019-10-14 18:00:00 P000002550 0 S000000009
10 23Z02T 7991 2019-10-14 13:41:00 2019-10-14 15:30:00 P000001103 0 S000000010
# ℹ 603 more rows
# ℹ Use `print(n = ...)` to see more rows
# Séjours porteurs de code de soins palliatifs hors du GHM de soins palliatifs
> sejours_tbl %>% filter(!(GHMC %in% ghm_sp)) %>% semi_join(rums_tbl %>% inner_join(diags_tbl %>% filter(DIAG== cim_sp))) %>% collect
Joining with `by = join_by(NRUM)`
Joining with `by = join_by(NDA)`
# A tibble: 27 × 7
GHMC GHS DENT DSORT IPP DS NDA
<chr> <dbl> <dttm> <dttm> <chr> <int> <chr>
1 90Z00Z 9999 2019-12-09 14:00:00 2019-12-09 17:30:00 P000001980 0 S000000059
2 05M124 1770 2020-12-08 15:37:00 2020-12-18 07:55:00 P000002870 10 S000000511
3 06M133 2178 2020-12-21 15:28:00 2021-02-02 18:30:00 P000004800 43 S000000685
4 10M163 3959 2020-12-31 18:35:00 2021-01-07 13:00:00 P000002883 7 S000000765
5 10M163 3959 2021-03-09 11:22:00 2021-03-16 18:45:00 P000001941 7 S000001612
6 06C14J 1982 2021-03-17 06:51:00 2021-03-17 16:22:00 P000002748 0 S000001733
7 04M093 1163 2021-03-18 08:18:00 2021-04-05 09:45:00 P000000510 18 S000001746
8 09C03J 3323 2021-03-22 09:46:00 2021-03-22 18:00:00 P000000597 0 S000001787
9 11M041 4293 2021-03-27 07:34:00 2021-03-28 12:00:00 P000004806 1 S000001859
10 06M04T 2199 2021-04-04 10:19:00 2021-04-05 16:00:00 P000002220 1 S000001967
# ℹ 17 more rows
# ℹ Use `print(n = ...)` to see more rowsIl est tout à fait possible de sauvegarder la requête en l’attribuant à un objet :
# création de la requête
> requete <- sejours_tbl %>% filter(!(GHMC %in% ghm_sp)) %>% semi_join(rums_tbl %>% inner_join(diags_tbl %>% filter(DIAG== cim_sp)))
Joining with `by = join_by(NRUM)`
Joining with `by = join_by(NDA)`
# (pas de sortie écran lors de la création,
# les "Joining with" apparaissent parce que je n'ai pas explicitement
# spécifié les jointures et dplyr les a déduites)
# exécution de la requête (on pourrait bien sûr l'attribuer à une
# variable vu que c'est un tibble tout ce qu'il y a de plus standard)
> requete %>% collect
# A tibble: 27 × 7
GHMC GHS DENT DSORT IPP DS NDA
<chr> <dbl> <dttm> <dttm> <chr> <int> <chr>
1 90Z00Z 9999 2019-12-09 14:00:00 2019-12-09 17:30:00 P000001980 0 S000000059
2 05M124 1770 2020-12-08 15:37:00 2020-12-18 07:55:00 P000002870 10 S000000511
3 06M133 2178 2020-12-21 15:28:00 2021-02-02 18:30:00 P000004800 43 S000000685
4 10M163 3959 2020-12-31 18:35:00 2021-01-07 13:00:00 P000002883 7 S000000765
5 10M163 3959 2021-03-09 11:22:00 2021-03-16 18:45:00 P000001941 7 S000001612
6 06C14J 1982 2021-03-17 06:51:00 2021-03-17 16:22:00 P000002748 0 S000001733
7 04M093 1163 2021-03-18 08:18:00 2021-04-05 09:45:00 P000000510 18 S000001746
8 09C03J 3323 2021-03-22 09:46:00 2021-03-22 18:00:00 P000000597 0 S000001787
9 11M041 4293 2021-03-27 07:34:00 2021-03-28 12:00:00 P000004806 1 S000001859
10 06M04T 2199 2021-04-04 10:19:00 2021-04-05 16:00:00 P000002220 1 S000001967
# ℹ 17 more rows
# ℹ Use `print(n = ...)` to see more rowsExplorer la projection vers la base de données
Comme expliqué, dbplyr sert à requêter une base en écrivant un pipeline dplyr au lieu du code SQL, cependant celui-ci reste explorable. Nous avons 2 fonctions pour cela
show_query()
Cette fonction, appliquée à une requête, affiche le code qui va être transmis au moteur de base de données. Dans notre exemple :
> requete %>% show_query()
<SQL>
SELECT `LHS`.*
FROM (
SELECT `sejours`.*
FROM `sejours`
WHERE (NOT((`GHMC` IN ('23Z02Z', '23Z02T'))))
) AS `LHS`
WHERE EXISTS (
SELECT 1 FROM (
SELECT `rums`.*, `DIAG`, `TYPE`, `NDIAG`
FROM `rums`
INNER JOIN (
SELECT `diags`.*
FROM `diags`
WHERE (`DIAG` = 'Z515')
) AS `RHS`
ON (`rums`.`NRUM` = `RHS`.`NRUM`)
) AS `RHS`
WHERE (`LHS`.`NDA` = `RHS`.`NDA`)
)Comme vous pouvez le voir, dbplyr a traduit le code dplyr en code SQL nécessaire à notre requête ; il a fait les substitutions de variables et de fonctions nécessaires pour que le code soit adapté au moteur et a même adapté semi_join() qui est un type de jointure qui n’est pas géré normalement.
Ca n’est pas obligatoirement le code que vous auriez produit à la main, mais il fonctionne.
Le plan d’exécution interne
Il est aussi possible d’obtenir le plan d’exécution interne d’une requête c’est à dire comment elle va être découpée et exécutée par le moteur. Pour cela on demande explain() (explain est une fonction générique qui peut s’appliquer à divers objets en R, dans notre cas, vous pouvez l’appliquer sur une requête mais aussi sur une tbl) :
> requete %>% explain
<SQL>
SELECT `LHS`.*
FROM (
SELECT `sejours`.*
FROM `sejours`
WHERE (NOT((`GHMC` IN ('23Z02Z', '23Z02T'))))
) AS `LHS`
WHERE EXISTS (
SELECT 1 FROM (
SELECT `rums`.*, `DIAG`, `TYPE`, `NDIAG`
FROM `rums`
INNER JOIN (
SELECT `diags`.*
FROM `diags`
WHERE (`DIAG` = 'Z515')
) AS `RHS`
ON (`rums`.`NRUM` = `RHS`.`NRUM`)
) AS `RHS`
WHERE (`LHS`.`NDA` = `RHS`.`NDA`)
)
<PLAN>
id parent notused detail
1 2 0 216 SCAN sejours
2 12 0 0 CORRELATED SCALAR SUBQUERY 4
3 17 12 216 SCAN rums
4 33 12 53 SEARCH diags USING AUTOMATIC PARTIAL COVERING INDEX (DIAG=? AND NRUM=?)Nous avons alors la requête SQL mais aussi un plan d’exécution expliquant ce que va faire le moteur SQLITE. Cette sortie par contre n’est pas standardisée pour un retraitement informatique, c’est plus ou moins à destination d’un humain. Voici par exemple ci-dessous la sortie explain() d’une requête sur les bases nationales donc via le moteur teradata :

Le but de cette fonctionnalité est de permettre de débugger votre requête si les données sont incohérentes ou les performances décevantes.
Combiner la puissance de la base de données avec les retraitements R
Lors d’un traitement, nous pouvons décider qui travaille en fonction d’où on place le collect() :
Ce qui est avant le collect() est traité par la base de données, ce qui est après est traité par R.
> sejours_tbl %>%
inner_join(patients_tbl) %>%
mutate(CMD = substr(GHMC, 1, 2)) %>%
group_by(SEXE, CMD) %>%
summarise(n = n(),dms = mean(DS)) %>%
# traité par la BDD jusqu'ici
collect %>% ##############################################################
# traité par R à partir d'ici
pivot_wider(names_from="SEXE",values_from=c("n","dms"))
Joining with `by = join_by(IPP)`
`summarise()` has grouped output by "SEXE". You can override using the `.groups` argument.
# A tibble: 25 × 5
CMD n_F n_H dms_F dms_H
<chr> <int> <int> <dbl> <dbl>
1 01 215 201 1.81 1.90
2 02 218 189 0.0183 0.0794
3 03 48 63 0.5 0.222
4 04 239 195 3.90 3.99
5 05 282 281 1.52 2.21
6 06 670 544 1.21 1.29
7 07 95 109 5.71 3.70
8 08 414 369 3.07 4.32
9 09 142 115 3.30 3.69
10 10 102 82 5.45 5.09
# ℹ 15 more rows
# ℹ Use `print(n = ...)` to see more rowsLe résultat sera strictement le même si vous mettez le collect() avant le group_by(), cependant le traitement du regroupement sera fait pas R et non par le moteur de base. Ce qui peut avoir des impacts en terme de performance (selon le nombre de lignes à récupérer via le réseau par exemple).
Dans le cas d’uns base de données hébergée sur un serveur dédié (généralement bien dimensionné), il est souvent plus « rentable » de lui faire faire le maximum du traitement.
Les limites du système
L’équivalence automatique des verbes et fonctions R vers SQL
Bien entendu, dbplyr ne va pas pouvoir TOUT transformer en code SQL, ce langage ayant un but précis limitant sa polyvalence. De même, il n’est pas toujours possible de convertir une donnée ou fonction spécifique ; seules les plus fréquentes sont prévues, n’espérez donc pas que votre fonction personnalisée soit automatiquement transcrite en SQL ou en procédure stockée.
Par contre, il est tout à fait possible, si vous avez défini des fonctions personnalisées directement sur la base de données ou si vous voulez appeler des fonctions précises de la base dans vos traitements de les passer lors de la construction de requête. Par exemple :
> patients_tbl %>%
mutate(
alea_perso= sql("random()/92233720368547758.07"),
alea_dbplyr = runif()) %>%
show_query()
<SQL>
SELECT
`patients`.*,
random()/92233720368547758.07 AS `alea_perso`,
(0.5 + RANDOM() / 18446744073709551616.0) AS `alea_dbplyr`
FROM `patients`Nous voyons ci dessus alea_perso= créé manuellement en passant du code SQL brut tandis que alea_dbplyr= est produit par traduction de la fonction runif(). Par contre si vous passez une fonction inconnue (tant en auto-traduction ou par le moteur de base), la requête échouera.
L’accès à des ressources composites
Imaginons que patients et sejours sont 2 dataframes contenant la même chose que les tables pointées par patients_tbl et sejours_tbl :
patients <- dbReadTable(con, "patients") # un tibble/dataframe
patients_tbl <- tbl(con, "patients") # un tbl dynamique
sejours <- dbReadTable(con, "sejours") # un tibble/dataframe
sejours_tbl <- tbl(con, "sejours") # un tbl dynamiqueAlors on pourrais être tenté de faire
patients %>% left_join(sejours_tbl)
patients_tbl %>% left_join(sejours)Ces deux appels mélangeant des pommes et des poires (tibbles locaux et tbls en base) finissent avec une erreur mais dont le message nous donne un espoir :
Error in `auto_copy()`:
! `x` and `y` must share the same src.
ℹ `x` is a <tbl_SQLiteConnection/tbl_dbi/tbl_sql/tbl_lazy/tbl> object.
ℹ `y` is a <tbl_df/tbl/data.frame> object.
ℹ Set `copy = TRUE` if `y` can be copied to the same source as `x` (may be slow).En effet, selon la configuration de la base de données et les quantités de données dans les tables concernées, l’ajout du paramètre copy= réglé à TRUE dans la jointure va entrainer une recopie de la table non disponible vers l’autre mode de stockage (soumis à droits divers pour les bases de données). Ainsi :
> patients_tbl %>% inner_join(sejours, copy=TRUE) %>% show_query()
Joining with `by = join_by(IPP)`
<SQL>
SELECT `patients`.*, `GHMC`, `GHS`, `DENT`, `DSORT`, `DS`, `NDA`
FROM `patients`
INNER JOIN `dbplyr_eQn29OQvG0`
ON (`patients`.`IPP` = `dbplyr_eQn29OQvG0`.`IPP`)
# On voit bien le nom de la table temporaire crée>
> patients_tbl %>% inner_join(sejours, copy=TRUE)
Joining with `by = join_by(IPP)`
# Source: SQL [?? x 11]
# Database: sqlite 3.47.1 [C:\Users\fsenis\Documents\R\atih_demo.sqlite]
NOM PRENOM DDN SEXE IPP GHMC GHS DENT
<chr> <chr> <date> <chr> <chr> <chr> <dbl> <dttm>
1 SUDRE PIERRETTE 1942-10-19 F P000004646 23M20Z 7990 2021-02-04 15:11:00
2 MOTTIN ALAIN 1960-09-19 H P000003594 16M133 6194 2022-02-08 14:02:00
3 ROSTAING PATRICK 1955-08-21 H P000004313 06M12T 5381 2021-10-28 15:22:00
4 LHOTE NOELE 1951-01-02 F P000003113 23Z02T 7991 2020-12-22 13:50:00
5 LHOTE NOELE 1951-01-02 F P000003113 23Z02Z 7994 2021-04-29 09:45:00
6 FERCHAUD MIGAEL 1981-04-08 H P000001973 06K04J 2121 2021-02-01 07:08:00
7 NEGRIER JEREMIE 1979-12-19 H P000003669 06M033 2131 2021-07-21 18:54:00
8 NEGRIER JEREMIE 1979-12-19 H P000003669 07M02T 5409 2021-07-19 12:24:00
9 MEYRE MONIQUE 1941-07-22 F P000003468 07M071 2529 2022-01-05 13:58:00
10 KESKAS MURIELLE 1962-03-14 F P000002723 11M044 4296 2020-12-25 19:45:00
# ℹ more rows
# ℹ 3 more variables: DSORT <dttm>, DS <int>, NDA <chr>
# ℹ Use `print(n = ...)` to see more rowsOn voit bien de part les entêtes de résultat que nous sommes dans l’affichage d’une requête côté base de données dont il faudra collect()er le contenu pour l’avoir dans R.
Nous pouvons faire le traitement inverse (données principales locales, jointure avec données distantes) :
> patients %>% inner_join(sejours_tbl, copy=TRUE)
Joining with `by = join_by(IPP)`
# A tibble: 6,895 × 11
NOM PRENOM DDN SEXE IPP GHMC GHS DENT
<chr> <chr> <date> <chr> <chr> <chr> <dbl> <dttm>
1 SUDRE PIERRETTE 1942-10-19 F P000004646 06K04J 2121 2021-01-06 08:58:00
2 MOTTIN ALAIN 1960-09-19 H P000003594 02C05J 424 2021-12-06 06:00:00
3 MOTTIN ALAIN 1960-09-19 H P000003594 02C05J 424 2022-01-03 06:00:00
4 ROSTAING PATRICK 1955-08-21 H P000004313 23M20T 7989 2021-09-20 15:54:00
5 LHOTE NOELE 1951-01-02 F P000003113 04M111 5194 2021-07-01 15:40:00
6 FERCHAUD MIGAEL 1981-04-08 H P000001973 02C05J 424 2020-12-07 11:00:00
7 FERCHAUD MIGAEL 1981-04-08 H P000001973 08C481 2885 2021-11-21 17:00:00
8 NEGRIER JEREMIE 1979-12-19 H P000003669 20Z051 5797 2021-03-27 01:04:00
9 MEYRE MONIQUE 1941-07-22 F P000003468 08C38J 2840 2021-02-08 06:00:00
10 MEYRE MONIQUE 1941-07-22 F P000003468 06K04J 2121 2022-01-26 06:56:00
# ℹ 6,885 more rows
# ℹ 3 more variables: DSORT <dttm>, DS <int>, NDA <chr>
# ℹ Use `print(n = ...)` to see more rowsLe résultat est cette fois-ci directement un tibble vu que nous sommes en local.
Il n’en reste pas moins que ces manœuvres sont une consommation inutile de ressources en règle générale. Il vaut donc mieux planifier et passer par un prétraitement avec un collect() puis un traitement local en R.
Si vous attaquez directement le serveur de base de données principale de votre DPI1, il est TRES probable que les droits utilisateurs vous interdisent l’accès en écriture et en création de table (ce qui vous permettrait de totalement casser la base live du DPI), attendez-vous à ce que ce type de traitement échoue dans le sens R -> BdD !
Conclusion
Avec cet article, vous êtes fins prêt à bidouiller mon mini-DPI et quand vous vous sentirez prêt d’attaquer votre DPI ou les bases nationales. Et comme d’habitude, n’hésitez pas à me contacter si vous avez besoin de précisions.
La prochaine fois, en bonus, diverses infos sur d’autres pans mais non indispensables pour la manipulation de données en lecture.
- C’est MAL de faire comme ça. Il est fortement conseillé de passer par une réplication temps réel sur un autre serveur (moins puissant que le serveur de production) sur lequel les droits sont réglés en lecture exclusive. ↩︎