

dans l’article Ajouter des regroupements de colonnes facilement pour plus de lisibilité grâce à kableExtra nous avons vu comment regrouper des colonnes.
Ce type de regroupement existe pour les lignes, cependant il est moins pratique à manipuler.
En fait , la logique R veut que les colonnes d’un jeu de données soient définies et fixées (donc « faciles » à manipuler), tandis que les lignes sont supposées être des « observations » (au sens statistique) et donc d’un nombre variable selon le traitement, l’échantillon… De plus, même s’il existe une propriété rownames() pour les dataframes, on l’utilise rarement et elle finit généralement à la valeur par défaut : un nombre entier croissant de 1 à chaque observation tandis qu’on utilise une colonne explicite du jeu de données pour stocker une éventuelle valeur descriptive pertinente. L’une des raisons est que les manipulations risquent d’écraser cette propriété sans qu’on s’en rende compte.
Principes de base
Il y a 2 moyens de créer des groupes de lignes. Je vous les illustre en HTML, mais quelque chose d’équivalent sera possible en LaTeX :
- Les séparer par une ligne d’entête :
| CMD | Catégorie | GHM | Sévérité |
| Traumatismes de la peau et des tissus sous-cutanés, âge inférieur à 18 ans | |||
| 09 | M | 02 | 1 |
| 09 | M | 02 | 2 |
| Greffes de peau et/ou parages de plaie pour ulcère cutané ou cellulite | |||
| 09 | C | 02 | 1 |
| 09 | C | 02 | 2 |
| 09 | C | 02 | 3 |
la fonction qui nous intéresse alors s’appelle pack_rows() (pour la petite histoire, elle s’appelle aussi group_rows() mais vu qu’il y a une fonction homonyme dans dplyr, le mainteneur de kableExtra a décidé de changer le nom pour éviter la confusion).
ou
- Faire courir une cellule verticalement :
| Libellé | CMD | Catégorie | GHM | Sévérité |
| Traumatismes de la peau et des tissus sous-cutanés, âge inférieur à 18 ans | 09 | M | 02 | 1 |
| 09 | M | 02 | 2 | |
| Greffes de peau et/ou parages de plaie pour ulcère cutané ou cellulite | 09 | C | 02 | 1 |
| 09 | C | 02 | 2 | |
| 09 | C | 02 | 3 |
alors la fonction qu’il nous faudra s’appelle collapse_rows().
La fonction collapse_rows()
Elle est ce qui se rapproche le plus du résultat de la fonction header_separate() que nous avons vu la dernière fois mais elle ne fonctionne pas du tout de la même façon.
Cette fonction attend dans le paramètre columns= un vecteur numérique représentant les colonnes dont les valeurs sont à regrouper. L’ordre des lignes n’est pas modifié. Il convient donc de « préformer » les données avant d’attaquer la mise en page (c’est à dire avant l’appel à kable()).
RSA %>%
mutate(CMD = substr(GHMOUT, 1, 2),
CATGHM = substr(GHMOUT, 3, 3),
GHM = substr(GHMOUT, 1, 5)) %>%
filter(CMD == "23") %>%
count(CMD, CATGHM, GHM, SEVOUT) %>%
kable() %>%
collapse_rows(columns = c(1, 2, 3)) %>%
kable_classic_2(lightable_options = "striped")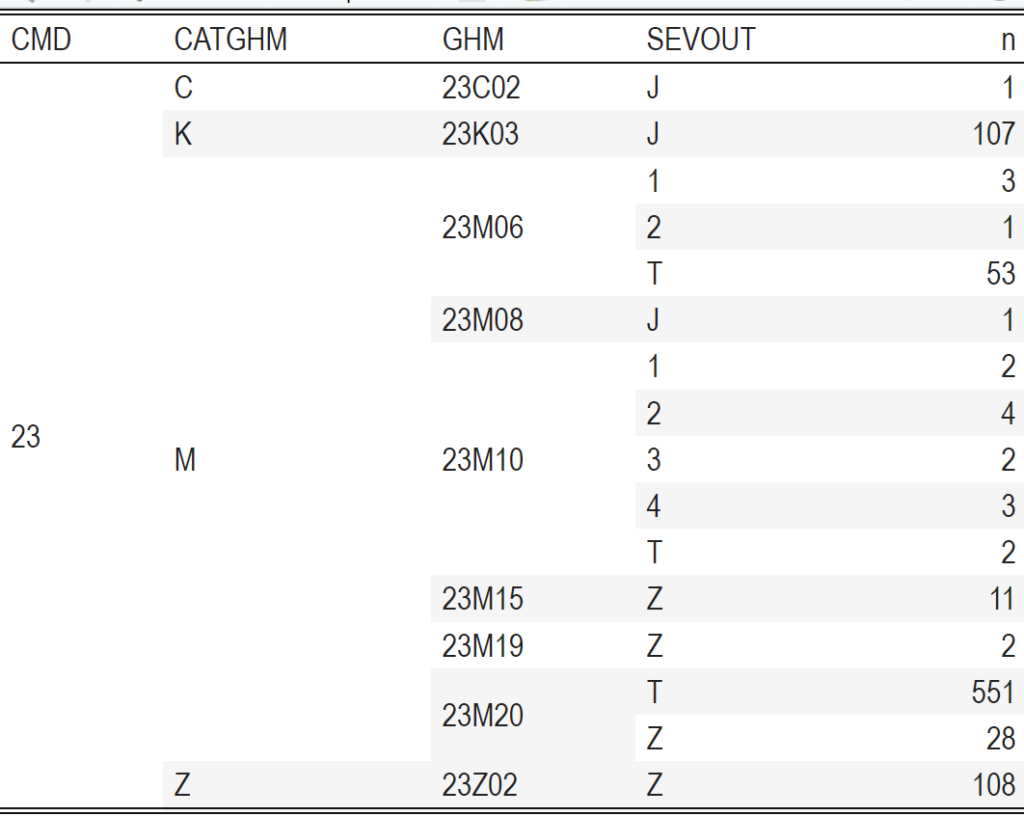
Cette méthode a comme principal problème d’être difficile à lire si il y a beaucoup de sous-items (les valeurs de la colonne parente n’apparaissant qu’une fois sur toute la hauteur des lignes regroupées).
De même, si nous utilisions le code pour fusionner la colonne SEVOUT, certains regroupements n’auront pas de sens :
RSA %>%
mutate(CMD = substr(GHMOUT, 1, 2),
CATGHM = substr(GHMOUT, 3, 3),
GHM = substr(GHMOUT, 1, 5)) %>%
filter(CMD == "23") %>%
count(CMD, CATGHM, GHM, SEVOUT) %>%
kable() %>%
collapse_rows(columns = c(1, 2, 3, 4)) %>%
kable_classic_2(lightable_options = "striped")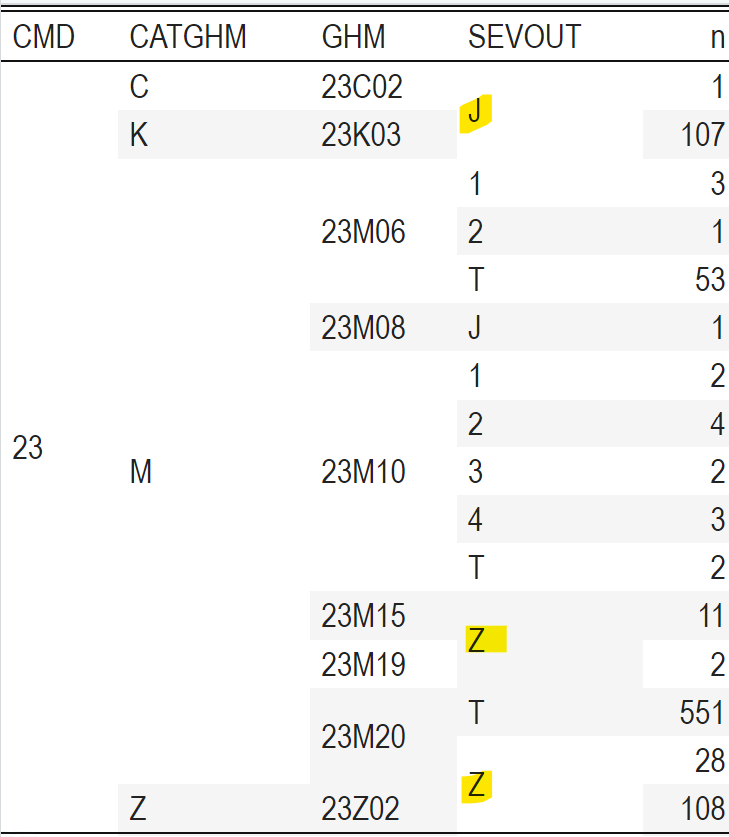
Voyez comment les valeurs de SEVOUT égales ont été fusionnées sans que cela n’ait de sens quant à la valeur hiérarchique des GHS. C’est pour cela que je vous conseille de n’utiliser collapse_rows() que sur un jeu qui s’y prête.
Comment définir les colonnes
L’autre problème est que les colonnes sont à spécifier par position. Souvent, c’est possible car l’aspect de la table est important et nous le fixons nous même (souvent, il s’agit des ‘n’ premières colonnes). Cependant il peut arriver que nous ne maitrisions pas le résultat (par exemple après un pivot_wider() quand le jeu de données n’est pas exhaustif). pour cela nous devons pouvoir identifier la position de chaque colonne à étendre. Je vous donne donc un petit bout de code qui permet juste cela :
# Les colonnes que nous voulons fusionner :
index <- c("CMD", "GHM")
# on crée un jeu de données temporaire
temp <- RSA %>%
mutate(CMD = substr(GHMOUT, 1, 2),
CATGHM = substr(GHMOUT, 3, 3),
GHM = substr(GHMOUT, 1, 5)) %>%
filter(CMD == "23") %>%
count(CMD, CATGHM, GHM, SEVOUT)
# La formule magique pour trouver les index
col_temp <- which(names(temp) %in% index)
# Et la suite du traitement
temp %>% kable() %>%
collapse_rows(columns = col_temp) %>%
kable_classic_2(lightable_options = "striped")En spécifiant de cette façon, en plus, les noms de colonnes dans l’index qui n’existeraient pas sont simplement ignorés.
La fonction pack_rows()
Le principe qui régit cette méthode nécessite d’identifier manuellement ou par programmation les lignes à traiter donc le découpage en groupe de lignes repose en fait sur un indexage numérique des lignes.
Voici un petit exemple en spécifiant manuellement le regroupement :
RSA %>%
mutate(CMD = substr(GHMOUT, 1, 2),
CATGHM = substr(GHMOUT, 3, 3),
GHM = substr(GHMOUT, 1, 5)) %>%
filter(CMD=="23") %>%
count(CMD, CATGHM, GHM, SEVOUT) %>%
kable() %>%
pack_rows(index = c("Type = C" = 1,
"Type = K" = 1,
"Type = M" = 13,
"Type = Z" = 1)) %>%
kable_classic_2(lightable_options = "striped")
qui nous donne :
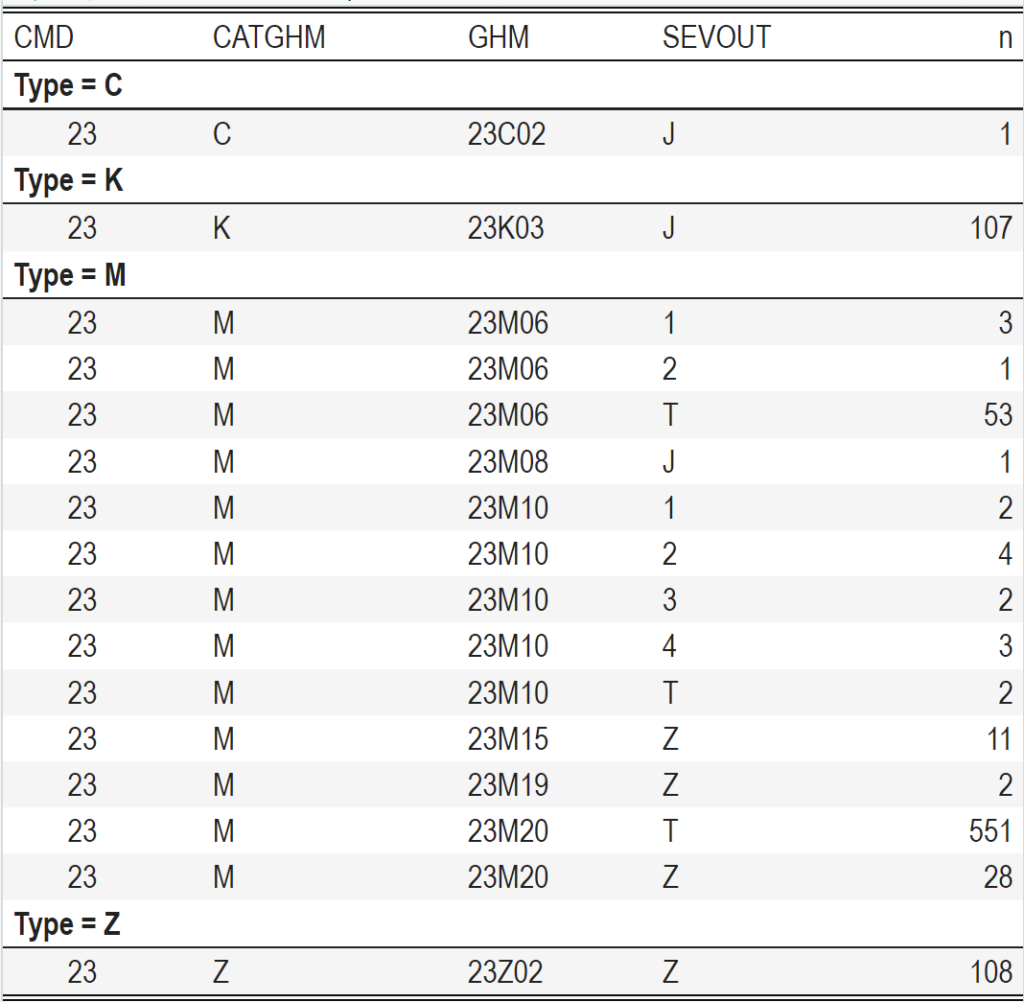
Vous voyez ici que l’index= passé à pack_rows() détaille manuellement le titre et le nombre de ligne de chaque regroupement. Accessoirement, vous pouvez remarquer qu’il n’y a pas besoin que les colonnes soient dans le jeu de données lui-même. On peut tout à fait avoir :
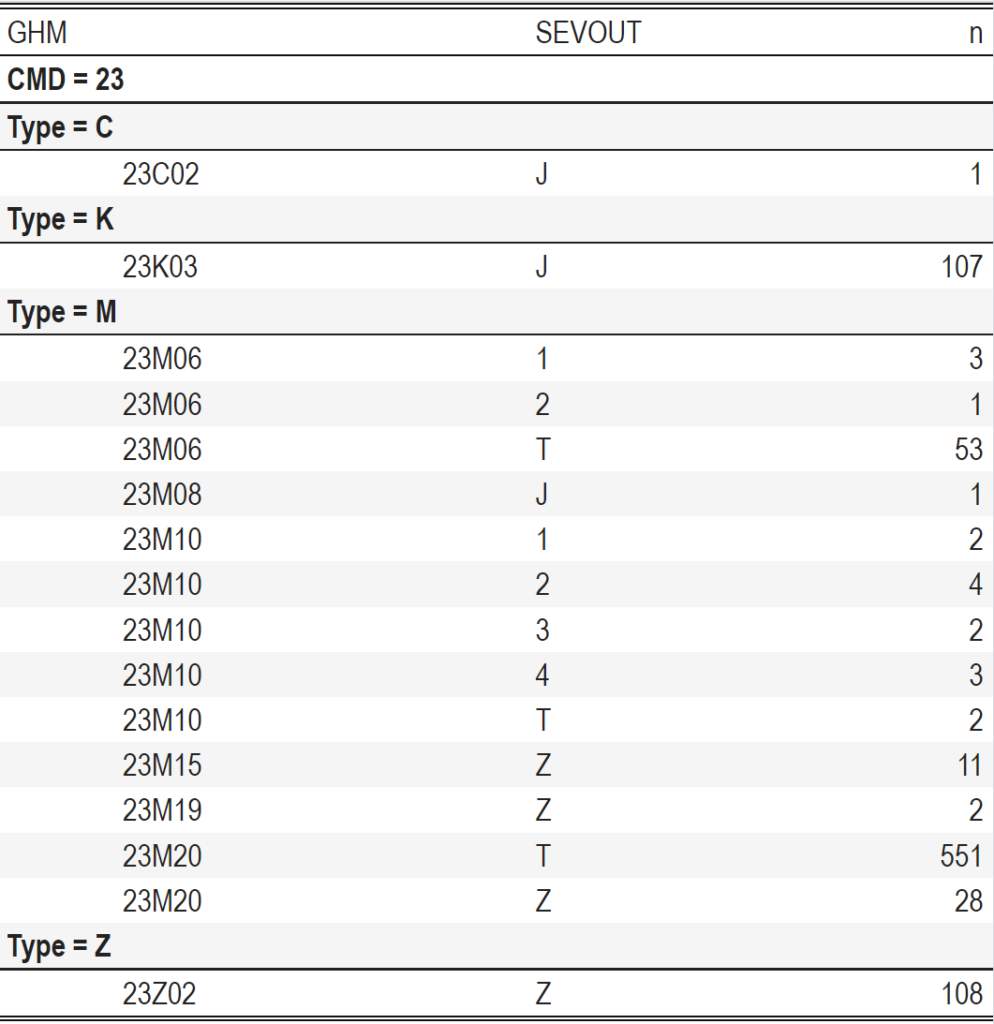
Je vous laisse imaginer le code. (la solution est en fin d’article)
Il est possible aussi d’utiliser pack_rows() en lui passant 3 paramètres de longueur 1 : group_label=, start_row= et end_row=. Et, il est tout à fait possible de l’appeler plusieurs fois pour définir plusieurs groupes et sous-groupes :
RSA %>%
mutate(CMD = substr(GHMOUT, 1, 2),
CATGHM = substr(GHMOUT, 3, 3),
GHM = substr(GHMOUT, 1, 5)) %>%
filter(CMD == "23") %>%
count(GHM, SEVOUT) %>%
kable() %>%
pack_rows(group_label = "CMD = 23" ,start_row = 1,end_row = 16) %>%
pack_rows(group_label = "Type = M" ,start_row = 3,end_row = 15) %>%
pack_rows(group_label = "CMD = 23, Type = M, GHM = 10" ,start_row=7, end_row =11) %>%
kable_classic_2(lightable_options = "striped")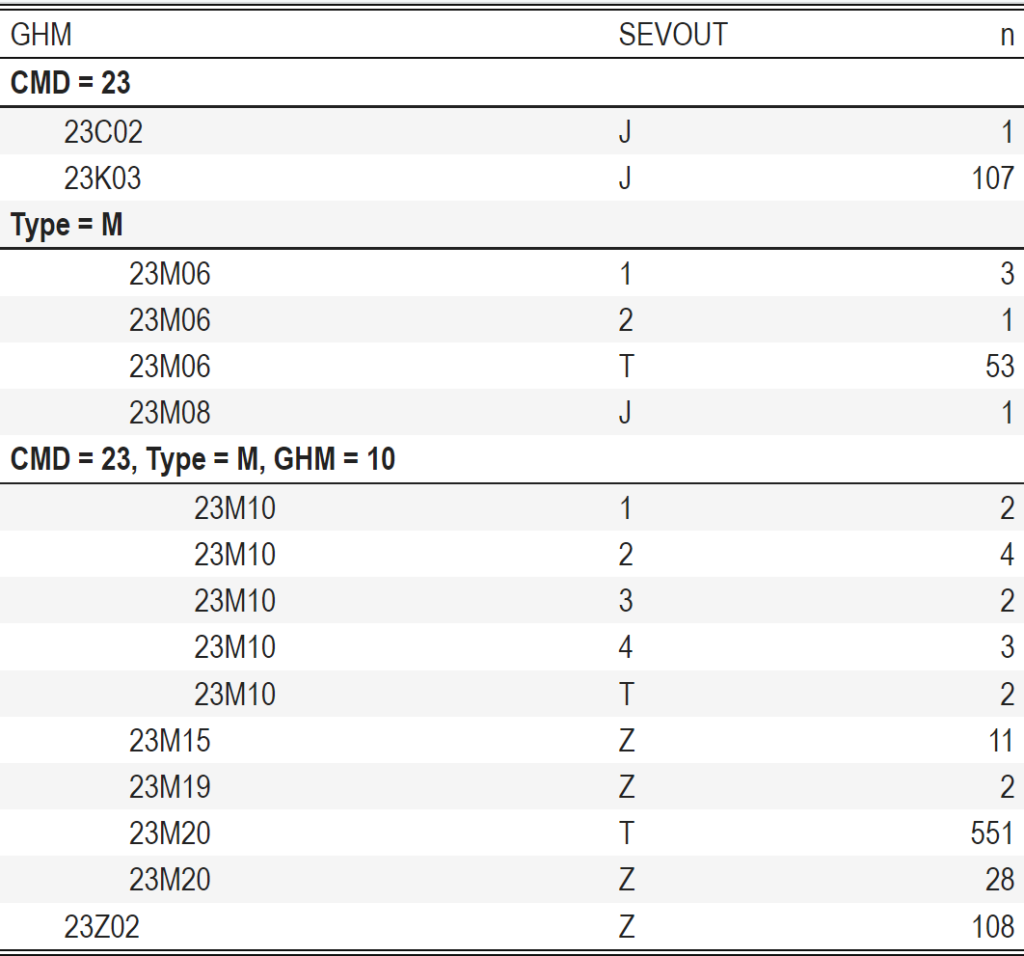
Vous pouvez bien visualiser le regroupement par l’indentation de la première colonne.
Comment définir les groupes ?
Comme dans le cas précédent, il va falloir trouver une façon de faire les découpages plus ou moins automatiquement car rien ne garantit le nombre de lignes de chaque groupe.
Ecrivons donc une fonction prepare_pack() qui fonctionnera pour 1 colonne. Elle prendra en entrée, le jeu de données qui sera passé à kable() et le nom de la colonne qui nous intéresse.
prepare_pack <- function(x,col){
tmp <- x[[col]] %>% # on ne garde que la colonne qui nous intéresse
rle # à laquelle on applique la fonction "run length encoding"
# rle, consiste a encoder des données en comptant le nombre d'occurences successives
# justement.
# Pour la petite histoire, c'est la méthode de compression de base des formats BMP
# et TIFF ainsi que du protocole des télécopieurs (pour les dinosaures comme moi
# qui traineraient ici).
# En français, on dit "codage par longueur de plage".
# on met au format attendu par le paramètre "index=" de pack_rows()
setNames(tmp$lengths, tmp$values)
}
# On peut ensuite faire comme pour collapse_rows() :
# on crée un jeu de données temporaire
temp <- RSA %>%
mutate(CMD = substr(GHMOUT, 1, 2),
CATGHM = substr(GHMOUT, 3, 3),
GHM = substr(GHMOUT, 1, 5)) %>%
filter(CMD == "23") %>%
count(CMD, CATGHM, GHM, SEVOUT)
# La formule magique pour trouver les index et leur taille
col_temp <- prepare_pack(temp, "CATGHM")
# Et la suite du traitement
temp %>% kable() %>%
pack_rows(index = col_temp) %>%
kable_classic_2(lightable_options = "striped")Conclusion
Voilà, nous sommes désormais en mesure de faire des regroupements sur les lignes et sur des colonnes, ainsi que des lignes de résumés. Il n’y a pas à dire, cela commence à ressembler à quelque chose !
Comme toujours, il existe d’autres paramètres que l’on peut passer à ces fonctions pour affiner l’aspect. Je vous laisse les explorer.
One more thing…
Voici la solution à l’exercice ci-dessus :
RSA %>%
mutate(CMD = substr(GHMOUT, 1, 2),
CATGHM = substr(GHMOUT, 3, 3),
GHM = substr(GHMOUT, 1, 5)) %>%
filter(CMD=="23") %>%
count(GHM, SEVOUT) %>%
kable() %>%
pack_rows(index= c("CMD = 23" = 16)) %>%
pack_rows(index = c("Type = C" = 1,
"Type = K" = 1,
"Type = M" = 13,
"Type = Z" = 1)) %>%
kable_classic_2(lightable_options = "striped")