
Comme annoncé précédemment, aujourd’hui nous allons faire de la mise en forme conditionnelle et en particulier de la mise en couleur.
Qu’est-ce qu’une couleur dans R ?
R n’a pas d’objet spécifique pour définir une couleur, il s’agit d’une chaîne de caractères qui peut se spécifier soit symboliquement par un nom, par exemple "red", "green", "blue", etc. soit par une représentation en chaîne du champ RVB traditionnel dans un format hexadécimal. On écrit alors "#ff0000", "#00ff00", "0000ff", soit par une matrice de taille n x 3 possédant 3 valeurs « red », »green », « blue » sur une échelle de 0 à 255.
Il est possible de lister les couleurs symboliques prédéfinies reconnues dans la librairie de base via une fonction qui porte bien son nom : colors()
> colors()
[1] "white" "aliceblue" "antiquewhite"
[4] "antiquewhite1" "antiquewhite2" "antiquewhite3"
[7] "antiquewhite4" "aquamarine" "aquamarine1"
[10] "aquamarine2" "aquamarine3" "aquamarine4"
[13] "azure" "azure1" "azure2"
...L’appel ne prend pas de paramètre pertinent (il y en a un : distinct= qui élimine (TRUE) ou non (FALSE) les « synonymes ») et n’a que peut d’intérêt dans le cadre d’un programme.
Pour définir plus finement une couleur, on doit utiliser la notation hexadécimale (ou les matrices mais on le fait rarement). R fournit des fonctions de bases pour faciliter leur création.
rgb(), pour commencer, est la plus directe. Il convient de lui passer au minimum 3 paramètres : red=, green= et blue= contenant une valeur numérique. S’y ajoute maxColorValue= qui en quelque sorte contient le dénominateur sur lequel les valeurs précédentes vont être rapportées (par défaut 255) et enfin alpha= qui gère la transparence (par défaut aussi 255 qui correspond à « totalement opaque » mais rapporté à maxColorValue= si le paramètre est utilisé).
> rgb(50, 50, 50, maxColorValue = 100)
[1] "#808080"
# 80 (on dit huit-zéro, pas quatre-vingt car on est pas en base 10) en hexadécimal
# donne 128 en base 10
# L'opacité rajoute un doublet de caractères en fin de chaine,
# en son absence, la couleur est considérée totalement opaque
> rgb(50, 50, 50, maxColorValue = 100, alpha = 50)
[1] "#80808080"
# Içi une opacité de 50% donc.ce qui correspond à une couleur contenant 50% de chaque couleur primaire et donne donc presque du gris moyen (« gray50 ») semi opaque :
> col2rgb("Gray50")
[,1]
red 127
green 127
blue 127
# Ce qui correspond en hexadécimal à #7F7F7FCela nous permet de voir la fonction col2rgb() qui fait la conversion entre une chaine de caractère (la valeur symbolique ou hexadécimale) et le triplet numérique correspondant.
Pourquoi cette base 256 (255 en décimal = #FF en hexadécimal) par défaut ? C’est parce que c’est le plus grand nombre stockable dans un octet qui est un des types ancestraux de base de la segmentation mémoire. Il y a de nombreuses raisons qu’on peut évoquer toutes aussi vraies, la mienne : du temps où les ordinateurs en avaient peu, c’était plus pratique et c’était la meilleure utilisation de l’espace disponible.
Il existe d’autres façons de créer une couleur en utilisant les autres échelles colorimétriques courantes à savoir HSV (Teinte Saturation Valeur) ou HCL (Teinte Chroma Luminance). Je ne rentrerai pas dans les détails mais sachez juste que ces 2 derniers modes sont plus pratiques pour réaliser des dégradés ou des palettes. Si le sujet vous intéresse, vous pouvez consulter la page Wikipedia qui est assez claire : Teinte saturation lumière (Wikipédia FR) et très complète en anglais. La fonction est assez logiquement hsv() attendant les paramètres h=, s=, v= et alpha= (ces valeurs sont toutes à définir dans l’intervalle [0;1]) ou pour hcl() h= (intervalle [0;360°]), c= (variable selon la teinte) , l= (intervalle [0;100]), alpha= (intervalle [0;1]).
Sachez qu’il existe aussi une fonction col2hcl() qui est un faux-ami. Elle prend une couleur RGB ou symbolique, la transforme en HCL puis lui applique des modifications passée via les paramètres h=, c= et l= avant de la retransformer en RGB. Ce n’est donc pas le pendant de col2rgb().
Par exemple pour générer un rouge sombre (valeur à 50%) : EXEMPLE
> hsv(1, 1, .5)
[1] "#800000"
> hcl(h = 0,c = 155,l = 1)
[1] "#800000"Dans la suite, nous allons autant que possible utiliser des valeurs symboliques pour la lisibilité.
Dans le vif du sujet
Dans le cadre de cet article, nous allons écrire un petit contrôle prospectif sur les durées de séjour et rendre le tout assez visuel grâce à la mise en couleur du fond de la case. Le but est de rechercher les périmètres de séjours où une analyse sur dossier pourrait permettre de vérifier si la prise en charge ne pourrait pas bénéficier d’une optimisation afin de diminuer la durée de séjour.
Note préalable à l’attention des puristes :
Je ne cherche pas dans cet article la rigueur statistique mais juste à déclencher ou tempérer un signal d’alerte.
En effet, comparer une moyenne générale à la médiane d’un échantillon n’a souvent pas trop de sens d’autant plus, on le sait, que les durées de séjours dans un GHM ne sont pas des valeurs centrées et symétriques. Cependant, la médiane a cet avantage d’être moins sensible aux valeurs extrêmes atypiques donc juste pour confirmer visuellement une alerte cela fera l’affaire.
Dans l’idéal, il conviendrait de faire un test statistique sur les 2 populations mais nous n’avons pas les données, et cela n’est le but premier de l’article.
J’espère que les statisticiens et épidémiologistes qui passeront ici me pardonneront… Promis, un jour je ferai un article plus rigoureux orienté traitements statistiques.
Pour arriver à nos fins, nous allons étudier le RSA et comparer la durée moyenne de séjour et la durée médiane de séjour par GHM aux valeurs attendues au niveau national pour :
- DMS nationale
- EXB
- EXH
Et nous colorerons la case ainsi :
| DS < BB | DS >= BB et DS < DMS | DS >= DMS et DS < BH | DS >= BH |
| 1 | 5 | 9 | 15 |
| cornflowerblue | lightgreen | orange | indianred1 |
Pour la lisibilité, je vais créer des colonnes supplémentaires dans le tableau qui contiendront les couleurs. Comprenez que ce n’est pas réellement nécessaire.
Initialisation
Créez un nouveau fichier Rmarkdown dans Rstudio via l’icone-menu de création. Je vous laisse configurer votre entête comme vous le désirez dans l’assistant. Il faudra ensuite enlever le contenu d’exemple par défaut bien sûr
Une fois n’est pas coutume, on va charger un RSA par découpage (voyez l’intro de l’article Etude de la RAAC grâce au RSA et R).
Il nous faudra aussi des éléments liés au GHM et au GHS. Ceux-ci se trouvent dans les fichiers excel GHMINFO et GHSINFO de l’archive OVALIDE.ZIP disponible sur le site de l’ATIH1. Il faut bien sûr prendre ceux correspondant à l’année à étudier et au type d’établissement (public/privé).
Nous allons réutiliser du code déjà écrit lors de la série d’article sur la valorisation des GHS.
D’abord chargeons les librairies dont nous allons avoir besoin. Il nous faudra dplyr, knitr et kableExtra, readr et readxl. (knitr n’est pas strictement nécessaire, c’est juste pour avoir kable() qui peut être remplacé par kbl() de la librairie kableExtra).
Nous définirons les valeurs par défaut dans l’entête du fichier (dans params:).
Pour ma part, je range les fichiers de façon ordonnée par année dans un répertoire « Documents\EXPORTS\REF\<ANNEE>\OVALIDE\ » dans lequel je dézippe le fichier OVALIDE.ZIP .
---
title: "Votre Titre"
output: html_document
date: "Selon comment vous avez configuré l'assistant"
params:
annee: 2023
statut: "public"
basedir_ovalide: "~/EXPORT/REF/%ANNEE%/OVALIDE"
fichier_rsa: "~/EXPORT/ETAB/2023/exemple.rsa"
---
```{r setup, include = FALSE}
# Chargement des librairies. Dans cet ordre pour éviter les conflits imprévus.
library(knitr)
library(kableExtra)
library(dplyr)
library(readr)
library(readxl)
# ici nous rajoutons les fonctions déjà écrites
# (dans la vraie vie, on les mettrait dans un fichier
# ".r" séparé que l'on chargerait via source("nom du fichier .r")
# Fonction de chargement de RSA (inchangée par rapport à la version
# précédente)
charge_RSA <- function(fichierRSA) {
read_fwf(
file = fichierRSA,
col_positions = fwf_cols(
NRSA = c(13,22),
GHMIN = c(31, 36),
RGHMIN = c(31, 35),
SEVIN = c(36, 36),
GHMOUT = c(42, 47),
RGHMOUT = c(42, 46),
SEVOUT = c(47, 47),
AGEA = c(53, 55),
AGEJ = c(56, 58),
SEXE = c(59, 59),
MOIS = c(62, 63),
ANNEE = c(64, 67),
GHS = c(96, 99),
DS = c(71, 74),
TOPUHCD = c(111, 111),
MINORE = c(112, 112),
RAAC = c(199, 199),
DP = c(212, 217),
DR = c(218, 223)
),
col_types = list(
col_character(),
col_character(),
col_character(),
col_character(),
col_character(),
col_character(),
col_character(),
col_number(),
col_number(),
col_character(),
col_number(),
col_number(),
col_number(),
col_number(),
col_character(),
col_character(),
col_character()
)
)
}
# Génération du chemin selon l'année (là aussi inchangée)
genereChemin = function(fp, annees){
lapply(annees, function(x){sub("%ANNEE%",x, fp)}) %>% as.character
}
```Nous rajoutons des fonctions simplifiées pour charger spécifiquement les champs qui nous intéressent dans les 2 fichiers qui vont nous servir (GHMINFO et GHSINFO).
```{r setup_suite, include = FALSE}
# Fonction de chargement des bornes tirées des GHS
charge_GHSINFO <- function(basedir,annee,statut) {
nom_fichier <- paste(genereChemin(basedir,annee),
"/GHSINFO_",
ifelse(statut=="prive","PRIV","PUB"),
".xlsx",
sep="")
read_excel(nom_fichier,
col_types = c("numeric", "skip", "numeric",
"numeric"),
col_names = c("GHS","BB","BH"),
skip = 1) %>%
distinct
}
# fonction pour charger le minimum nécessaire de GHMINFO
# (le GHM et la DMS nationale)
charge_GHMINFO <- function(basedir,annee,statut) {
nom_fichier <- paste(genereChemin(basedir,annee),
"/GHMINFO_",
ifelse(statut == "prive", "PRIV", "PUB"), ".xlsx", sep = "")
read_excel(nom_fichier,
col_types = c("text", "skip", "skip",
"skip", "skip", "skip", "numeric",
"skip", "skip", "skip", "skip", "skip",
"skip", "skip", "skip", "skip", "skip",
"skip", "skip"),
col_names = c("GHM","DMS"),
skip = 1)
}
```Comme vous pouvez le voir, j’ai créé un 2ème bloc de code (setup_suite). Cela n’est pas du tout obligatoire, c’est juste pour la lisibilité de l’article et du rmarkdown (en pratique courante, j’utiliserais une fonction déjà écrite qui charge les colonnes de façon exhaustive puis sélectionnerais uniquement celles qui m’intéressent afin de pouvoir avoir une fonction de base réutilisable).
Pour rappel, la fonction distinct() va simplifier les doublons existant dans ce fichier spécifique.
Nous pouvons donc maintenant charger les différentes données et en tirer des médianes et des moyennes par GHM :
RSA <- charge_RSA(params$fichier_rsa)
GHMINFO <- charge_GHMINFO(params$basedir_ovalide,params$annee,params$statut)
GHSINFO <- charge_GHSINFO(params$basedir_ovalide,params$annee,params$statut)
RSA_moyennes <- RSA %>% group_by(GHMOUT, RGHMOUT, SEVOUT, GHS) %>%
summarise(DSmed = median(DS),
DS = mean(DS),
N=n()) %>%
arrange(desc(N))Et les croiser :
RSA_moyennes <-RSA_moyennes %>%
left_join(GHMINFO, by = c("GHMOUT" = "GHM")) %>%
left_join(GHSINFO, by = c("GHS" = "GHS"))Vous pouvez bien sûr limiter le jeu aux colonnes pertinentes (je vous laisse choisir les pertinentes pour votre utilisation) ainsi qu’aux séjours où la comparaison est utile.
Enfin, il nous faut calculer la couleur de chaque ligne du jeu. Pour cela, nous allons définir une fonction (pour la lisibilité) qui reproduit algorithmiquement le tableau ci-dessus.
decoration <- function(x,BB,DMS,BH){
case_when(x <= BB ~ "cornflowerblue",
x <= DMS ~ "lightgreen",
x <= BH ~ "orange",
x > BH ~ "indianred1",
.default = "black"
)
}
# s'utilise dans un mutate() :
RSA_moyennes %>% mutate(couleur = decoration(DS, BB, DMS, BH))
Dans le case_when() nous n’avons pas à mettre les bornes basses car les conditions sont traitées dans l’ordre d’écriture : si x <= BB est VRAI, les autres alternatives ne sont pas considérées pour le résultat, si la condition est fausse c’est la suivante qui prend la priorité, et ainsi de suite jusqu’à ce que toutes soient épuisées et que la valeur soit celle prévue dans .default=…
Il ne nous reste plus qu’à en faire un kable() et le mettre en forme
```{r preparation_donnees}
# Tout le code ci-dessus en 1 bloc que l'on attribue à la variable :
RSA_moyennes <- RSA %>%
group_by(GHMOUT, SEVOUT, GHS) %>%
summarise(DSmed = median(DS),
DS = mean(DS),
N = n()) %>%
left_join(GHMINFO, by = c("GHMOUT" = "GHM")) %>%
left_join(GHSINFO, by = c("GHS")) %>%
mutate(couleur = decoration(DS, BB, DMS, BH),
cmedian = decoration(DSmed,BB,DMS,BH),
RGHMOUT = substr(GHMOUT,1,5)) %>%
ungroup %>%
filter(!(DS==0 & DMS==0)) %>%
arrange(desc(N))
# Pour la lisibilité j'ai supprimé les GHM dons la DMS nationale
# et la DMS établissement sont à "0 jours" qui correspondent à
# de l'ambu/HdJ bien bordé. C'est le rôle du filter() ci-dessus
# On crée le kable() et fait une mise en forme de base sur
# les 2 colonnes DS (= moyenne) et DSmed (= médiane).
kable(RSA_moyennes %>% select(RGHMOUT, SEVOUT, N, DS, DSmed, BB, DMS, BH),
format="pipe") %>%
kable_classic_2 %>%
column_spec(4, background = pull(RSA_moyennes, "couleur")) %>%
column_spec(5, background = pull(RSA_moyennes, "cmedian"))
```Pour rappel, pull() est une fonction qui transforme une colonne d’un dataframe en vecteur « nu ».
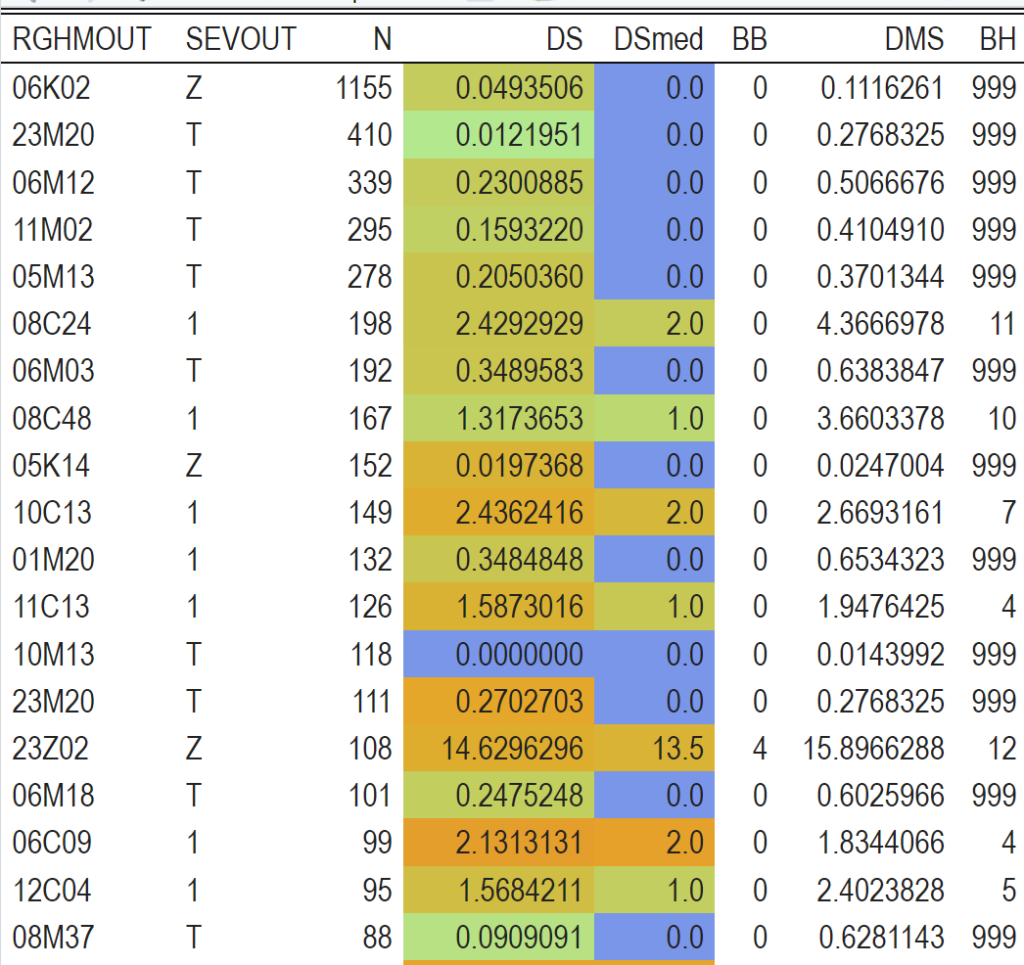
Le résultat dépendra bien sûr de votre RSA source. J’ai un peu triché pour que l’affichage montre les différentes possibilités :

…
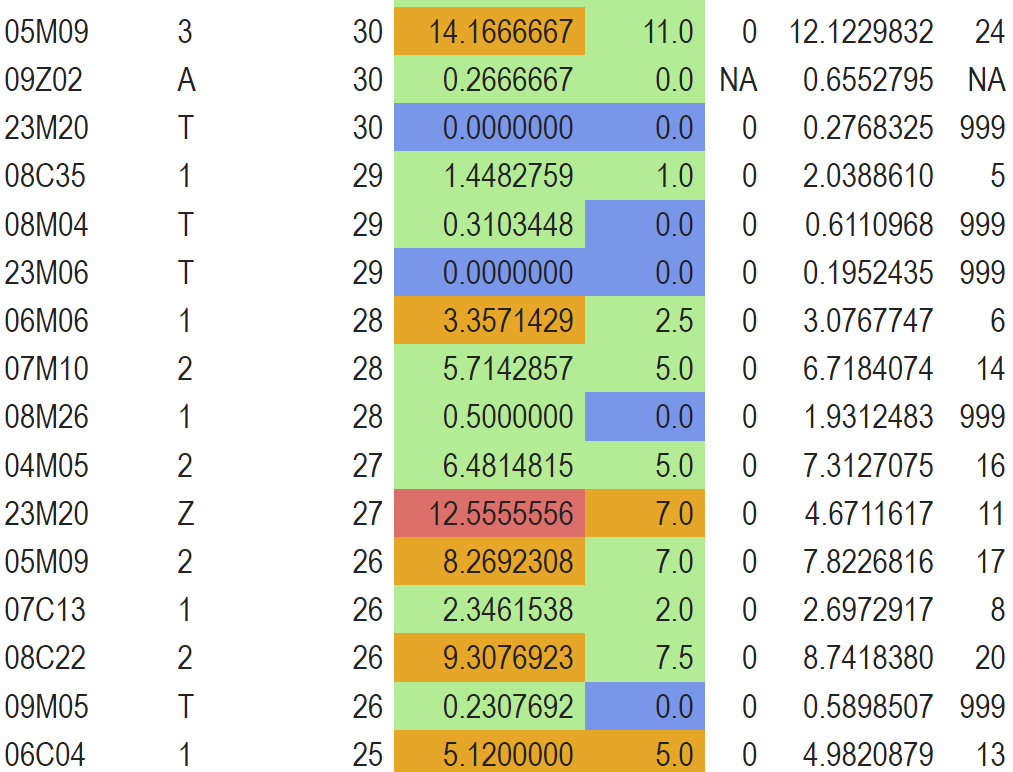
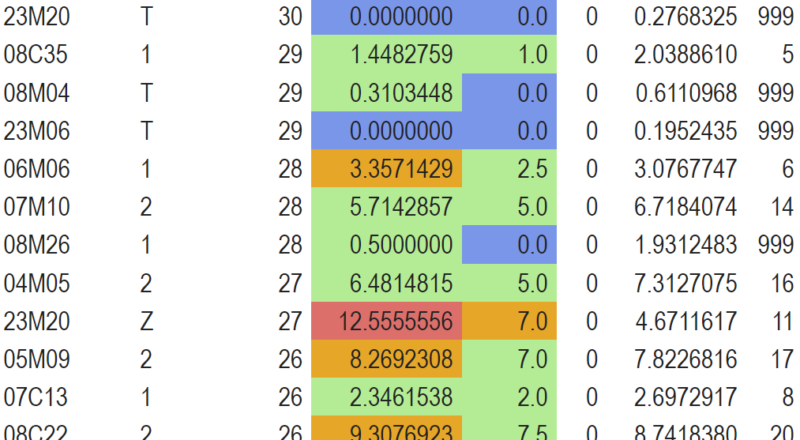
Analysons :
Nous voyons d’abord le début du tableau.
- Beaucoup de GHM non analysables sur BB et BH (ce sont des séjours en Z et T). Par contre systématiquement la DMS établissement est inférieure à la DMS nationale, c’est bien !
- Seuls 3 GHM sont de niveau 1 et là aussi on a une DMS établissement entre BB et DMS nationale.
Un peu plus bas dans la 2ème partie du tableau par contre :
- Le GHM 05M093 (et d’autres) à une DMS établissement supérieure à la DMS nationale sans dépasser la borne haute du GHM. La médiane est quand à elle nettement plus basse, signant probablement un ou plusieurs séjours atypiques qui plombent le résultat. Cela vaudrait le coup de se pencher sur la répartition plus fine.
- Et le GHM 23M20Z quant à lui est dans le ROUGE (avec une médiane ORANGE donc des atypies fort probables qui influent sur la moyenne mais sans pour autant être la seule raison). C’est plus inquiétant… Après ce n’est pas illogique vu la nature du GHM qui est un « fourre-tout » (Autres symptômes et motifs de recours aux soins de la CMD 23) en plus non sensible aux CMA… Cependant, cela vaudrait le coup de reprendre le codage de ces dossiers pour s’assurer qu’il n’y aurait pas possibilité de réorienter les séjours générant des EXH (DS>BH) vers des GHM soumis à CMA dans d’autres CMD.
Voilà, ce tableau nous a permis graphiquement de nous alerter sur des GHM sur lesquels être vigilants.
Passer en mode dégradé
Jusqu’à présent nous avons vu une transposition d’une échelle discrète (au sens mathématique : des valeurs individuelles et non continues) vers une gamme tout aussi discrète de couleurs réglées manuellement.
Il est cependant possible d’utiliser des dégradés. Il suffit que la fonction decoration() renvoie une valeur calculée de la couleur en fonction de son paramètre en entrée. Vous pouvez le faire vous-même par programmation, mais sachez que R a des fonctions déjà prédéfinies pour certains cas et de nombreuses bibliothèques qui vous évitent de réinventer la roue2.
En R (et en anglais en général), un dégradé se dit un « gradient » et l’application à un ensemble fini de couleurs définit une « palette ». Par défaut, il existe dans les librairies de base de R des fonctions pour créer des palettes :
rainbow(n, s = 1, v = 1, start = 0, end = max(1, n - 1)/n, alpha, rev = FALSE)heat.colors(n, alpha, rev = FALSE)terrain.colors(n, alpha, rev = FALSE)topo.colors(n, alpha, rev = FALSE)cm.colors(n, alpha, rev = FALSE)
Où n= définit le nombre de couleur que doit contenir le dégradé créé. Par exemple :
> rainbow(10)
[1] "#FF0000" "#FF9900" "#CCFF00" "#33FF00" "#00FF66"
[6] "#00FFFF" "#0066FF" "#3300FF" "#CC00FF" "#FF0099"Ce qui donne :
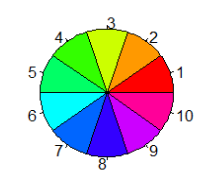
Comme leur nom l’indique, les fonctions créant des palettes ci-dessus ont une finalité :
rainbow()donne un arc en ciel (que l’on peut personnaliser en changeant les paramètress=etv=)heat.colors()est plus adapté à l’illustration de la chaleur (de « rouge braise » vers le « jaune pale flamboyant »)terrain.colors()permet de spécifier la nature de terrain d’une carte (du vert (plaine boisée) au blanc (enneigement) en passant par le marron (sol à nu))- tandis que
topo.colors()se spécialise plus sur l’altitude (du bleu (mer et profondeurs) au blanc (neige des sommets) en passant par le vert, le jaune et une version réduite deterrain.colors()) - enfin
cm.colors()permet de définir une palette centrée (un dégradé à gauche et un à droite avec le blanc au milieu)
Mais on peut aussi définir un dégradé « à la main » grâce à la fonction colorRamp() et ainsi que des palette grâce à sa collègue colorRampPalette().
colorRamp() et colorRampPalette()
colorRamp() est une fonction qui retourne une fonction (on appelle ça une « function factory ») qui elle-même attendra une valeur entre 0 et 1 et retournera la couleur concernée. Par exemple :
> degrade <- colorRamp(c("blue","red"))
# "dégrade" est une fonction qu'il faut appeler
# et renverra la couleur correspondant à la
# position continue x avec 0 <= x <= 1
> degrade(.50)
[,1] [,2] [,3]
[1,] 127.5 0 127.5
# soit la valeur moyenne (0,50) entre du bleu et du rouge
# Bien sûr cette fonction est vectorisée il est donc possible d'écrire
> degrade(c(0, 1, .5, .33, .40))
[,1] [,2] [,3]
[1,] 0.00 0 255.00
[2,] 255.00 0 0.00
[3,] 127.50 0 127.50
[4,] 84.15 0 170.85
[5,] 102.00 0 153.00Les paramètres principaux de colorRamp() sont un vecteur de couleurs qui viendront configurer le rendu sur l’espace [0;1], puis d’autres (bias=, space=, interpolate=) pour affiner l’aspect.
colorRampPalette(n,...) de son côté définit une palette de « n » couleurs sur le dégradé créé par colorRamp() grâce aux autres paramètres (...).
Nous avons cependant un problème, la fonction retournée par colorRamp() produit une matrice et non un vecteur de caractères :
> degrade(.25, .5, .75)
[,1] [,2] [,3]
[1,] 63.75 0 191.25
[2,] 127.50 0 127.50
[3,] 191.25 0 63.75Pour notre besoin, nous devons transformer ces triplets RGB en code hexadécimal. Assez étonnamment, il n’y a pas de fonction dans la librairie standard. Nous allons donc l’écrire, elle est assez simple et utilise rgb() que nous connaissons déjà :
rgb2hex <- function(x){
rgb(x[, 1], x[, 2], x[, 3], maxColorValue = 255)
}Elle parait simple et semble fonctionner mais pose un problème : elle ne gère pas le cas NA (et génère une erreur qui interrompt le traitement) nous allons donc la compléter pour gérer ce cas si il devait arriver (dans les faits, cela arrive lorsque le GHM est en CMD 90). Il y a plusieurs façons d’y parvenir et je vais directement montrer ma préférée : le subsetting (déjà utilisé dans l’optimisation de la fonction de valorisation) car le plus rapide et le plus dans l’esprit R :
rgb2hex <- function(x, na.color = "white"){
# On remplit le vecteur de résultat de la fonction
# avec la valeur par défault na.color=
resultat <- rep(na.color, nrow(x))
# Identifier les lignes sans NA
a_traiter <- complete.cases(x)
# Convertir uniquement les lignes valides en
# couleurs hexadécimales
resultat[a_traiter] <- rgb(x[a_traiter, 1], x[a_traiter, 2], x[a_traiter, 3],
maxColorValue = 255)
return(resultat)
}
#Et le résultat :
> rgb2hex(degrade(c(.25, .5, .75, NA)))
[1] "#3F00BF" "#7F007F" "#BF003F" "white"
> rgb2hex(degrade(c(.25, .5, .75, NA)), "black")
[1] "#3F00BF" "#7F007F" "#BF003F" "black" Notez qu’il n’est pas possible directement de faire des dégradés/palettes dont les couleurs ne sont pas uniformément réparties. Il y a là aussi plusieurs façon de faire et nous allons voir d’abord celle qui comme bien souvent semble la plus simple.
Nous pouvons insérer un case_when() afin de spécifier des palettes ou dégradés « par partie » par exemple. Ainsi nous pourrions écrire :
decoration <- function(x,BB,DMS,BH){
case_when(x <= BB ~ "cornflowerblue",
x <= DMS ~ rgb2hex(colorRamp(c("lightgreen","orange"))((x-BB)/(DMS-BB))),
x <= BH ~ rgb2hex(colorRamp(c("orange","indianred1"))((x-DMS)/(BH-DMS))),
x > BH ~ "indianred1",
.default = "black")
}Ce qui donne :
Cette fonction n’est pas très optimisée, normalement il faudrait créer préalablement les fonctions via colorRamp() (qui sont ainsi fixes et pas réécrites à chaque appel) puis ensuite appliquer toujours ces 2 même fonctions. Cela complexifie un peu le code car il faut les sauvegarder préalablement à l’appel à decoration().
Je vous mets une implémentation à titre d’illustration :
# On définit les 2 dégradés qui vont être utilisés
cr1 <- colorRamp(c("lightgreen", "orange"))
cr2 <- colorRamp(c("orange", "indianred1"))
# la fonction decoration() possède des colorRamp et de couleurs par défaut
# il suffit de passer les paramètres pour les surpasser
decoration2 <- function(x, BB, DMS, BH,
colorRamp1 = colorRamp(c("green","white")),
colorRamp2 = colorRamp(c("white","red")),
couleur_basse = "brown",
couleur_haute = "blue",
couleur_na = "black" ){
case_when(x <= BB ~ couleur_basse,
x <= DMS ~ rgb2hex(colorRamp1((x-BB)/(DMS-BB))),
x <= BH ~ rgb2hex(colorRamp2((x-DMS)/(BH-DMS))),
x > BH ~ couleur_haute,
.default = couleur_na)
}Cette nouvelle fonction est à la fois plus fonctionnelle vu qu’elle permet de personnaliser les couleurs et un petit coup de benchmarking avec microbenchmark vous prouvera qu’elle est 2 à 3 fois plus rapide quand on lui passe des colorRamp déjà calculées3.
Pourquoi le traitement est si long ?
Peut-être trouvez-vous que l’affichage de cette table est un peu (trop) longue. C’est qu’à la différence de Excel qui n’affiche qu’une 50aine de lignes à la fois à l’écran, kable() crée la totalité du tableau car sa finalité première est l’impression vers une page HTML ou LaTeX qui devient statique. Quoi qu’il en soit, la manipulation de l’aspect des kables étant basée sur le traitement du code généré au format texte, c’est un peu lent, oui… mais puissant.
Conclusion
Nous avons fini de manipuler les couleurs de notre tableau. Ce que nous avons appris cette fois-ci est transposable à toutes les autres options de ce genre. Une prochaine fois nous verrons