
Dans l’article Le typage des variables : les types de base nous avons vu le concept de vecteur (vector) et différents types de base.
Nous allons explorer aujourd’hui le type list.
Pour les python addicts (je vous vois !), il s’agirait d’une collection de type… list… (en ordre fixe et mutable)
Petit rappel sur les vecteurs.
Un vecteur est une structure de données ayant un type unique et un nombre quelconque de valeurs individuelles.
list est un des types de base, un vecteur de type list définit donc une collection de valeurs de type list.
La particularité de ce type est qu’il peut encapsuler n’importe quel autre type de données.
Voici pour rappel un vecteur de nombres (type float) :
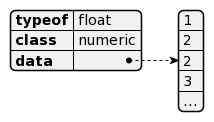
si on voulait utiliser une list, on obtiendrait :
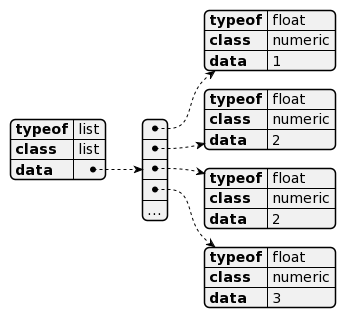
On voit donc que le principal intérêt d’une list est que le type est porté par l’item et non la collection. Les éléments qui la composent n’ont pas à être tous du même type ou de la même classe.
Il est tout à fait possible de faire :
> list(1L,2,"3",1i)
[[1]]
[1] 1 # type integer
[[2]]
[1] 2 # type float
[[3]]
[1] "3" # type character
[[4]]
[1] 0+1i # type complex
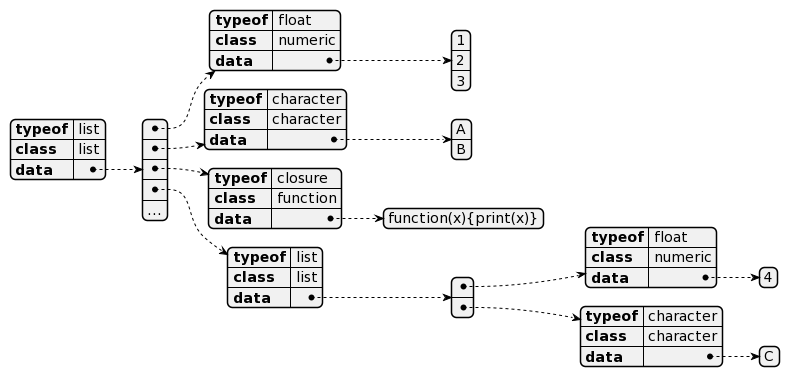
Mais plus encore, list accepte tout les types et toutes les classes de variables en son sein. Ainsi, il est possible d’y insérer des vecteurs de tous types et de toutes tailles y compris des list permettant ainsi une structure récursive :
> list(c(1,2,3),c("A","B"),function(x){print("x")},list(4,"C"))
[[1]]
[1] 1 2 3
[[2]]
[1] "A" "B"
[[3]]
function(x){print("x")}
[[4]]
[[4]][[1]]
[1] 4
[[4]][[2]]
[1] "C"
(notez la list en position 4 et sa présentation à l’écran indiquant l’index dans la list et la sous-list)
Et voici sa représentation structurelle :
Créer une liste
Nous avons déjà vu un moyen de créer une list : le constructeur list(...) attendant un nombre quelconque de valeurs qui seront insérées, dans l’ordre, au sein de la liste.
Il est possible d’initialiser une liste vide en appelant list() sans paramètres. Attention, à la différence d’un vecteur créé par exemple avec c(), un item de la list peut être NULL :
> c(1,NULL,3)
[1] 1 3 # vecteur de 2 float
> list(1,NULL,3)
[[1]]
[1] 1
[[2]] # list de 3 items dont la 2ème est NULL
NULL
[[3]]
[1] 3
Cela entraine de plus un effet de bord : une list(1,NULL,3) ne peut pas être coercée à un vecteur numérique car NULL n’est pas de type numérique mais de type NULL (un type pour lui tout seul) :
> as.numeric(list(1,NULL,3))
Error: 'list' object cannot be coerced to type 'double'
A noter aussi que si vous passez un vecteur à list(), vous ne créez pas une liste contenant les valeurs du vecteur mais une liste possédant un item unique contenant le vecteur en entier :
> list(c(1,2))
[[1]]
[1] 1 2
C’est une erreur classique quand on débute qui vaut souvent beaucoup d’arrachage de cheveux… permettant d’introduire le chapitre suivant :
Convertir en liste
Comme pour les autres types, il existe une fonction as.list() tentant de convertir son argument en liste. On peut donc y passer tous les types de vecteurs qui seront décomposés en autant d’items qu’ils ont de valeurs.
> as.list(c(1,2,3)) # Conversion d'un vecteur (de type float implicite) en list
Attention cependant à son usage avec un factor : l’intérêt du factor est perdu car les levels sont dupliqués aussi et non partagés. Il conviendra donc de préférer as.list(as.character(facteur)) pour se débarrasser de la structure factorisée sous-jacente.
> as.factor(c(1,2,3))
[1] 1 2 3
Levels: 1 2 3
> as.list(as.factor(c(1,2,3)))
[[1]]
[1] 1
Levels: 1 2 3
[[2]]
[1] 2
Levels: 1 2 3
[[3]]
[1] 3
Levels: 1 2 3
Tester une liste
is.list() permet de tester si la données est une liste. Il s’agit là de tester le type d’une donnée (la manière dont elle est stockée et accédée), cela veut dire qu’un objet hérité du type list amènera une réponse « Vrai »/TRUE. C’est le cas par exemple pour un objet de type data.frame :
> is.list(list(1,2,3))
[1] TRUE
> is.list(data.frame())
[1] TRUE
> class(data.frame())
[1] "data.frame"
> typeof(data.frame())
[1] "list" # Raison pour laquelle is.list() est TRUE
On peut donc utiliser la totalité des fonctionnalités adaptées aux listes sur la classe data.frame. Nous reviendrons sur les data.frame dans un article dédié (voire plusieurs) tant il y a à dire.
Accéder au contenu d’une liste
En lecture
Il est possible d’atteindre le contenu d’une list via un adressage ou subsetting :
Pour récupérer le contenu du 2ème emplacement, il suffit de faire :
> list(1,2,3)[[2]]
[1] 2
Notez les doubles-crochets qui demandent à retourner le contenu de l’item (ici un vecteur d’une seule valeur numérique : 2) et non le vecteur de list (une nouvelle liste qui contiendrait ici l’item 2).
Si nous ne précisons pas les [[ ]] mais mettons des crochets simples [ ], nous récupérons l’item (de type list) en lui-même :
> typeof(list(1,2,3)[2])
[1] "list"
> typeof(list(1,2,3)[[2]])
[1] "double"
Il est donc possible de « subsetter » une list comme tout autre vecteur, c’est à dire de restreindre une liste à certains de ses items grâce à la notation [] en y précisant un vecteur de type logique (True => garder, False => retirer) ou un vecteur entier (retournant une list contenant les items dans l’ordre du vecteur) :
> list(1,2,3)[c(T,F,T)]
[[1]]
[1] 1
[[2]]
[1] 3
> a[c(3,2)]
[[1]]
[1] 3
[[2]]
[1] 2
En écriture
Tout comme les autres types, il est possible de modifier les vecteurs contenus grâce à []<- :
# On crée une liste contenant 1,2,3
> a <- list(1,2,3)
> a
[[1]]
[1] 1
[[2]]
[2]
[[3]]
[1] 3
# On subsette grâce à un masque logique et on modifie le contenu via <-
> a[c(T,F,T)]<-"A"
> a
[[1]]
[1] "A"
[[2]]
[1] 2
[[3]]
[1] "A"
En cas de liste récursive, il est tout à fait possible de modifier en profondeur :
> a <- list("1",list("21","22",list("231","232","233")))
> a[[2]][[3]][2]<-"A"
> a
[[1]]
[1] "1"
[[2]]
[[2]][[1]]
[1] "21"
[[2]][[2]]
[1] "22"
[[2]][[3]]
[[2]][[3]][[1]]
[1] "231"
[[2]][[3]][[2]] # Le remplacement
[1] "A"
[[2]][[3]][[3]]
[1] "233"
Il faut comprendre a[[2]][[3]][2] comme :
Accède au contenu de l’item list n°2, dans cet item accède au contenu de l’item list n°3, dans cet item accède à l’item n°2 (et remplace-le)
Attention à bien mettre des [[ ]] afin de « rentrer » dans l’item (en dernier, on peut utiliser indifféremment [ ] et [[ ]]).
Ajouter des items
Il n’est pas possible d’ajouter des items per se car ce n’est pas la logique de R. Par contre, il est tout à fait possible de manipuler un vecteur et le réaffecter à la même variable dans le plus pur style R:
> a <- list(1,2)
> a
[[1]]
[1] 1
[[2]]
[1] 2
> a <- c(a,list(3))
> a
[[1]]
[1] 1
[[2]]
[1] 2
[[3]]
[1] 3
Dans les faits, on concatène (c()) 2 vecteurs de type list, a et un nouveau vecteur contenant 3 et on réaffecte ce nouveau vecteur à a.
Supprimer des items
Nous avons déjà vu comment faire : il suffit de subsetter (sélectionner les items qui nous intéressent) et réaffecter. Attention, cela change assez logiquement l’indexation des items (sans changer l’ordre cependant).
> a <- list(1,2,3)
> a <- a[2:3]
> a
[[1]]
[1] 2
[[2]]
[1] 3
Nous avons fait le tour des principales particularités des listes simples. La prochaine fois nous étudierons des variantes de listes, les listes nommées (et un petit mot en passant pour les dotted lists)